- 中国科学论文统计源期刊
- 中国科技核心期刊
- 美国化学文摘(CA)来源期刊
- 日本科学技术振兴机构数据库(JST)
机器学习在输血医学中的应用现状
前言
本期《输血医学新进展》聚焦于机器学习在输血医学中的最新应用进展。通过分析三篇前沿文献,涵盖了献血后铁回收率预测、基于深度学习的储存红细胞形态及质量评估,以及老年髋部骨折患者围手术期的输血风险预测,系统介绍了机器学习在血液质量管理及手术患者输血风险评估中的作用。相关研究不仅展示了机器学习在提升输血安全性和优化血液资源利用方面的潜力,也为临床实践提供了可靠的数据支持和方法参考,为精准输血管理奠定了基础。
预测献血后铁回收率的机器学习模型:模型开发和外部验证研究
编译者:曾媛 审校者:黄远帅
背景:
重复献血可导致或加重铁缺乏症,但个体风险存在差异。缺铁可引起疲劳、嗜睡、认知功能下降和不宁腿综合征等症状。一般采用检测献血前指尖血红蛋白来确保献血者达到最低献血要求阈值。然而,血红蛋白却不是反应铁储存的可靠标志物,不能识别许多低铁和缺铁献血者;而铁蛋白作为铁储存的标志物,识别缺铁献血者更加准确。但由于缺乏即时检测,无法进行献血前筛查,低铁蛋白献血者通常在献血后才能被告知他们的状态,并推迟延长献血期。因此,直接预测血红蛋白和铁蛋白机械学习模型有助于优化重复献血之间的间隔、管理与献血相关的缺铁并避免低效的血红蛋白延迟献血。此类机器学习模型尚未开发,也尚未在国际上得到外部验证,外部验证对于评估普遍性、为模型部署提供信息和防止可能导致不良后果的误差临床预测至关重要。因此,本研究旨在开发和外部验证预测献血者的血红蛋白和铁蛋白机器学习模型,以便定制献血者重复献血的最短间隔。
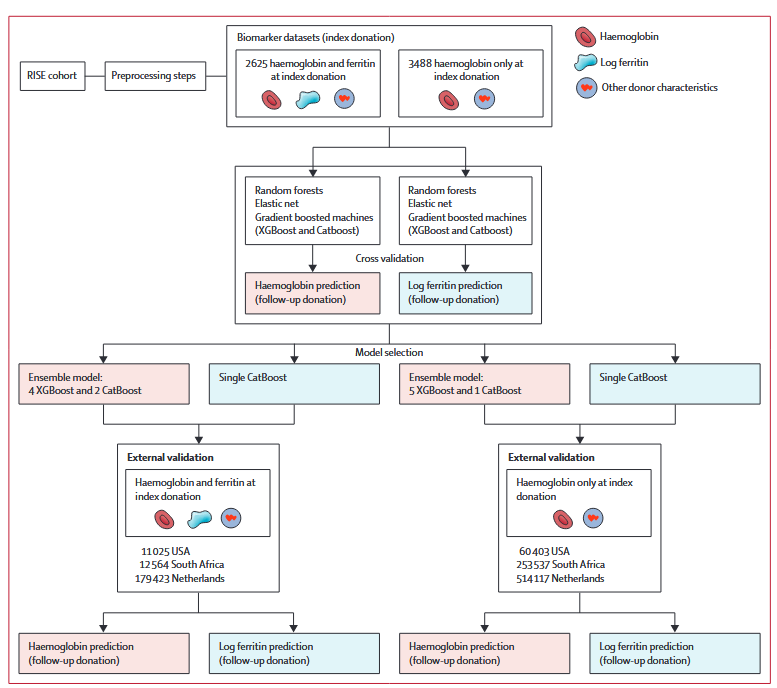
图 1研究方法流程图
纳入标准为首次献血(Index donation)和后续再次献血(Return donation)时测量的血红蛋白和铁蛋白的全血献血者。
主要结果:
表1 研究队列与外部队列捐献数据特征
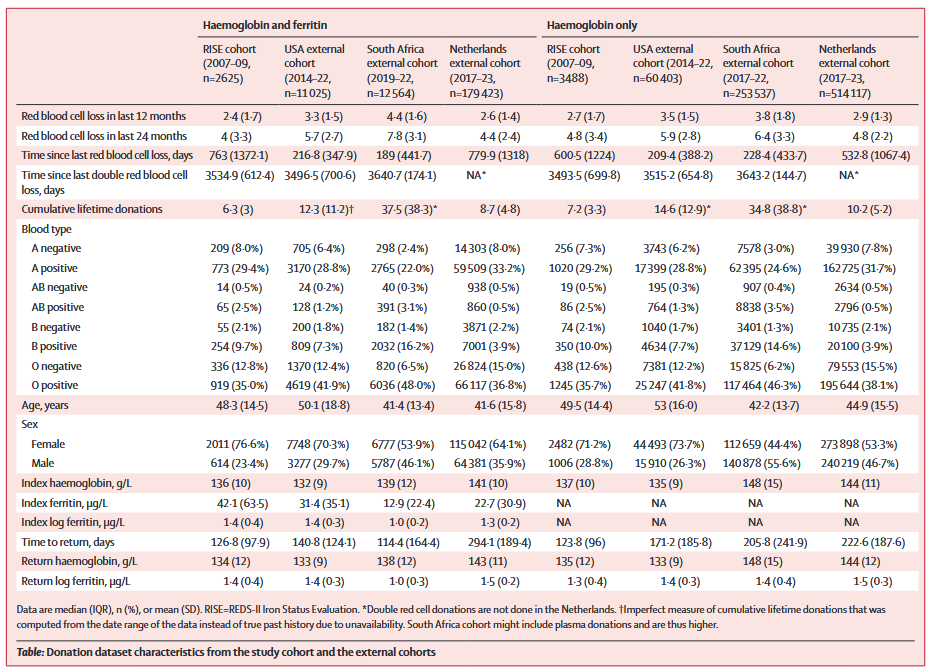
1.① 在预测再次献血的血红蛋白时,在两个数据集中性能最佳的非集成模型是XGBoost,但XGBoost和CatBoost模型的集成性能表现更好。性能最佳模型的嵌套交叉验证含血红蛋白和铁蛋白数据集(n = 2625)和仅含血红蛋白数据集(n = 3488)的均方根百分比误差(Root-mean-square percentage error,RMSPE)均为6.78。在包含11 000至514 000份捐赠的外部数据集中,RMSPE从未增长超过8%。② 在预测再次献血的铁蛋白时,血红蛋白和铁蛋白数据集(RMSPE=14.9)的性能优于仅含血红蛋白数据集(RMSPE=27.4)。总体而言,再次献血时献血员的血红蛋白含量的预测误差小于再次献血时献血员的铁蛋白含量。
2.在预测再次献血血红蛋白时,对预测的总体贡献最大的特征(Shapley additive explanations,SHAP)是首次献血时的血红蛋白,其次是再次献血的时间间隔和性别。在预测再次献血时献血员的铁蛋白含量时,首次献血时的log10铁蛋白和铁蛋白的贡献最大,其次是再次献血时间。当缺乏首次献血时的铁蛋白,预测再次献血铁蛋白时,性别贡献最大。
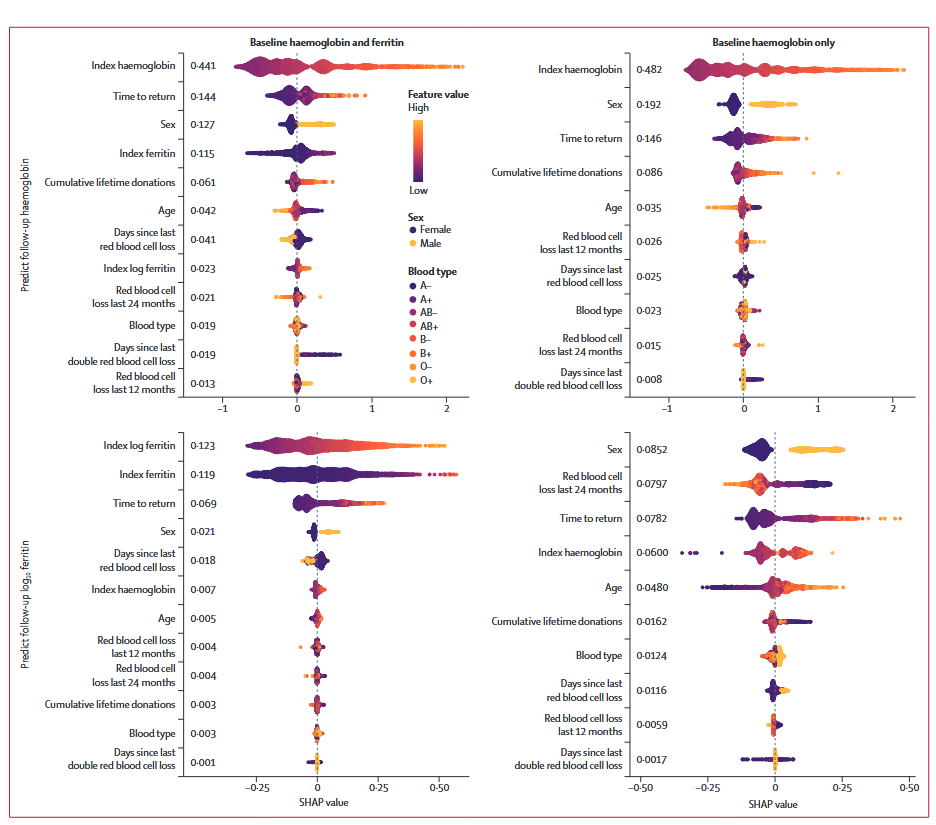
图2 SHAP特征贡献汇总图
3.在外部验证中,RMSPE在仅含血红蛋白数据集以及血红蛋白和铁蛋白数据集中分别增加不超过0.4%和28%。在预测再次献血时献血员的血红蛋白含量时,血红蛋白和铁蛋白数据集中的外部验证RMSPE均低于RISE中的嵌套交叉验证RMSPE:美国为4.6(-32%),南非为6.7(-2%),荷兰为6.3(-8%,图3)。在仅含血红蛋白数据集中,RMSPE在美国为7.2(+6%),在南非为7.3(+8%),在荷兰为5.9(-13%)。在预测再次献血时献血员的铁蛋白含量时,血红蛋白和铁蛋白数据集中的RMSPE在美国为14.9(+0.2%),南非为18.9(+28%),荷兰为15.1(+1%)。在仅含血红蛋白数据集中,美国的RMSPE为22.9(-17%),南非为27.6(+0.4%),荷兰为19.1(-31%)。
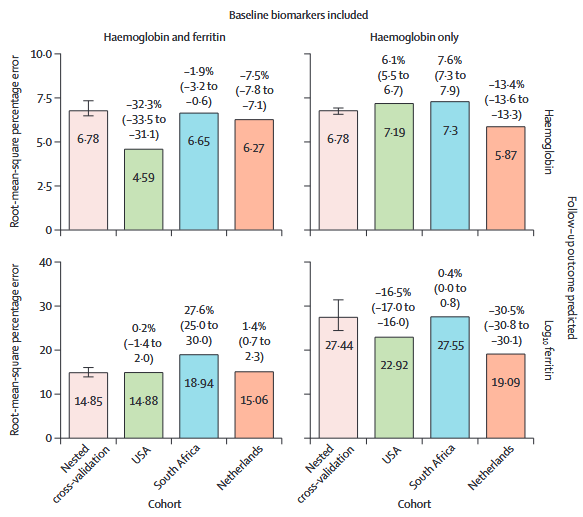
图3 外部验证结果(每个条形上显示的百分比增加表示RMSPE与RISE训练集中的RMSPE相比的百分比增加,括号中提供了95%CI,由1000个bootstrap重采样生成。)
4.与嵌套交叉验证相比,RMSPE在内部交叉验证中低3-12%。因此,与内部交叉验证误差相比,外部验证性能略逊一筹。但当将数据限制为每一献血者一个观察值和比较每个献血者RMSPE时,中外部验证性能的结论与主要分析相似。
5.在RISE的血红蛋白和铁蛋白数据集中,该模型准确预测了86%和82%的再次献血时铁蛋白分别<25μg/L和<12μg/L的献血者。如果没有铁蛋白作为预测因子,铁蛋白低于25μg/L的PPV(positive predictive value,阳性预测值)下降到72%,铁蛋白低于12μg/L 的PPV下降到59%。以铁蛋白为预测因子(87-88%)的NPV(negative predictive value,阴性预测值)也优于没有铁蛋白作为预测因子(70-75%)。但是,由于各国存在差异,在使用模型进行二分决策之前,需要对不同缺铁蛋白率的国家重新进行校准。
6. ① 在含血红蛋白和铁蛋白数据集中,再次献血的间隔时间越长,预测误差越高。除此之外,在美国和南非,西班牙裔和黑人捐献者与白人捐献者相比具有相似或更低的误差。而女性献血者的铁蛋白误差较高,血红蛋白误差较低。与15-24岁的年轻群体相比,在南非和荷兰,年龄较大的捐献者铁蛋白误差往往较低,在美国对血红蛋白的误差往往较低。② 在仅含血红蛋白数据集中,再次献血的间隔时间和性别对铁蛋白预测的影响因国家或地区而异。再次献血之前的间隔时间长可减少南非的误差,但却增加了美国和荷兰的误差。在美国,女性捐献者的误差较低,但在南非和荷兰队列中,女性捐献者的误差略高。
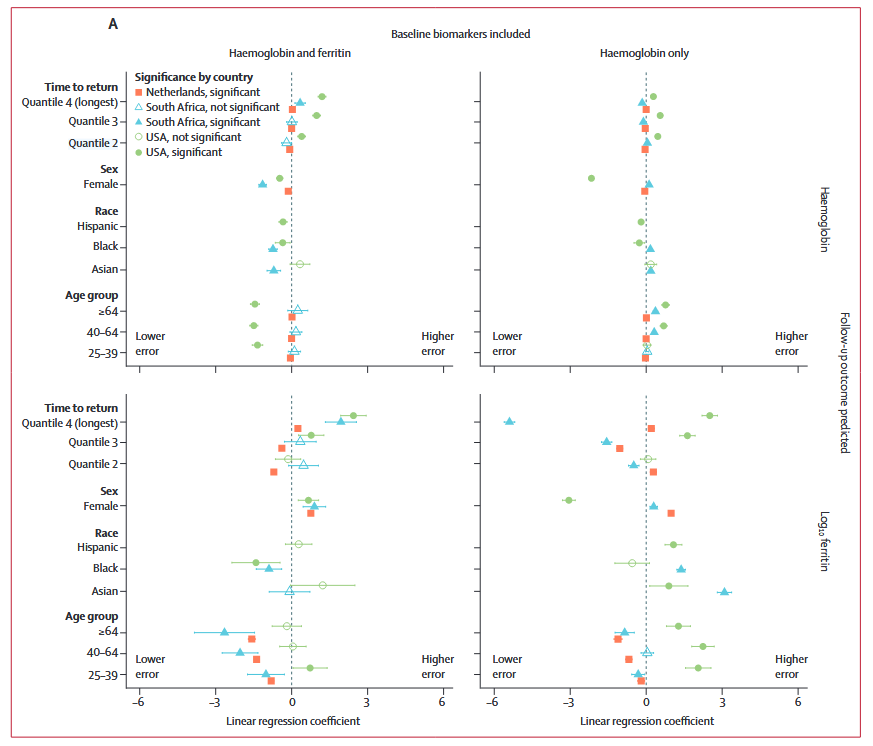
图4多元线性回归森林图
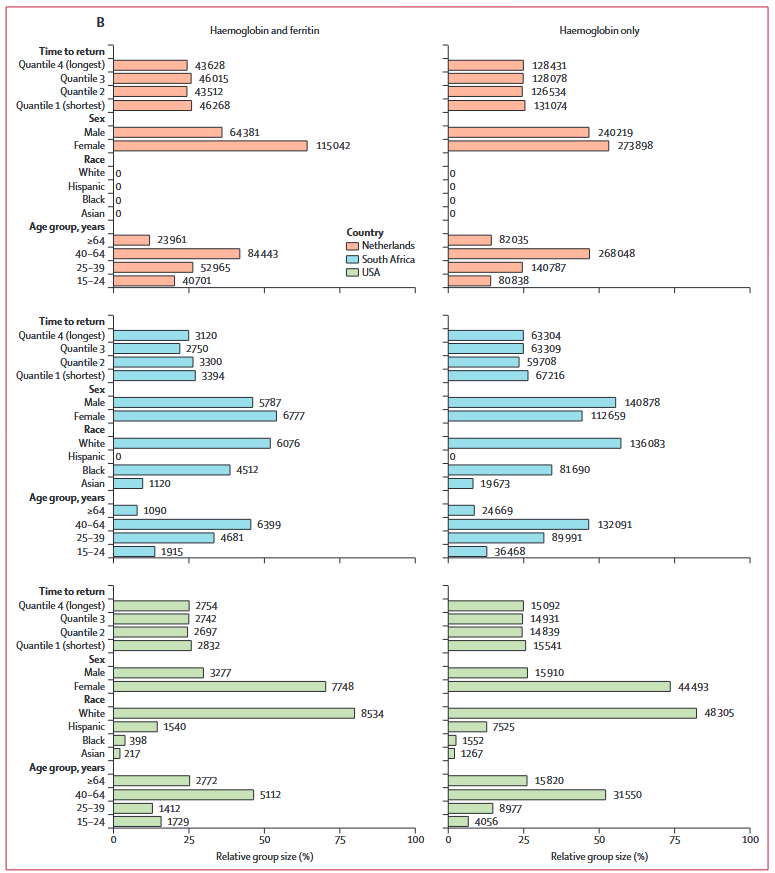
图5 按国家分层的每个捐赠者亚组的相对人口规模
结论:
机器学习模型在预测重复献血者血红蛋白和铁蛋白方面具有良好的性能,在美国、南非、荷兰等不同国家中得以推广,并且可以实现个性化的方法来高效控制低血红蛋白延迟和铁缺乏献血风险,同时有助于定制献血者重复献血间隔,确保充足的血液供应。
文献来源:
LiW, SuCY, MeulenbeldA, JagirdarH, JanssenMP, Swanevelder R, BruhnR, Kaidarova Z, BravoMD, CaoS, CusterB,vandenBergK, RussellWA.Machine-learning models to predict iron recovery after blood donation: a model development and external validation study. Lancet Haematol. 2025 Jun; 12(6):e431-e441. doi:10.1016/S2352-3026(25)00068-7. PMID:40447352.
基于深度学习的芯片级细胞形态分类用于血液质量评估
编译者:蔡智 审校者:黄远帅
背景
既往研究表明,储存红细胞在体外会逐渐发生溶血、能量耗竭、膜结构改变及氧释放能力下降等储存损伤(storage lesion),这会影响输血疗效。当前红细胞质量的评价依赖生化分析方法,如蛋白含量、ATP及2,3-DPG检测,以及Western blot、质谱和流式细胞术等手段。尽管这些方法能够反映红细胞的代谢与功能状态,但操作复杂且对脆弱细胞具有破坏性,同时难以真实反映细胞形态特征。红细胞在储存过程中会出现由正常双凹盘状到皱缩盘状、棘突球状,最终不可逆地退化为完全球形的连续形态学变化,这些形态学改变与生化指标高度相关。因此通过形态学观察和亚型计数进行质量评估具有可行性。但传统显微评估易受主观因素影响,且制片过程可能改变细胞状态。微流控技术与深度学习的结合为红细胞智能化评价提供新策略。微流控芯片可实现单层细胞通过和动态图像采集,避免细胞重叠和制片过程对形态的干扰;深度学习目标检测模型则可自动识别和分类红细胞亚型,实现高通量、低成本、客观的质量评估。本研究拟通过微流控芯片结合YOLOv4模型,对储存红细胞进行六个亚型分类并计算形态学指数(morphological index, MI),系统评估储血红细胞的形态特征及质量,为实现快速、准确的红细胞质量评价提供理论依据。
主要结果
1.研究设计了三种不同的芯片(长度2?cm,宽度100?μm,高度分别为25?μm、20?μm和12?μm)。血液样本经500倍稀释后注入芯片,当通道高度为25?μm或20?μm时,红细胞出现重叠现象,形成双层细胞(图1A、B)。降低通道高度至12?μm时,红细胞在有限空间和流体流动的作用下被均匀分散,并平整排列于微通道底部(图1C)。此设置确保红细胞以统一方式通过通道,并使拍摄的图像均为前视图,有利于后续形态学分析。当通道高度过低(<8?μm)时,红细胞易在入口处阻塞,因此实验最终选择通道高度为12?μm,以兼顾细胞分布均匀性与流动顺畅性。
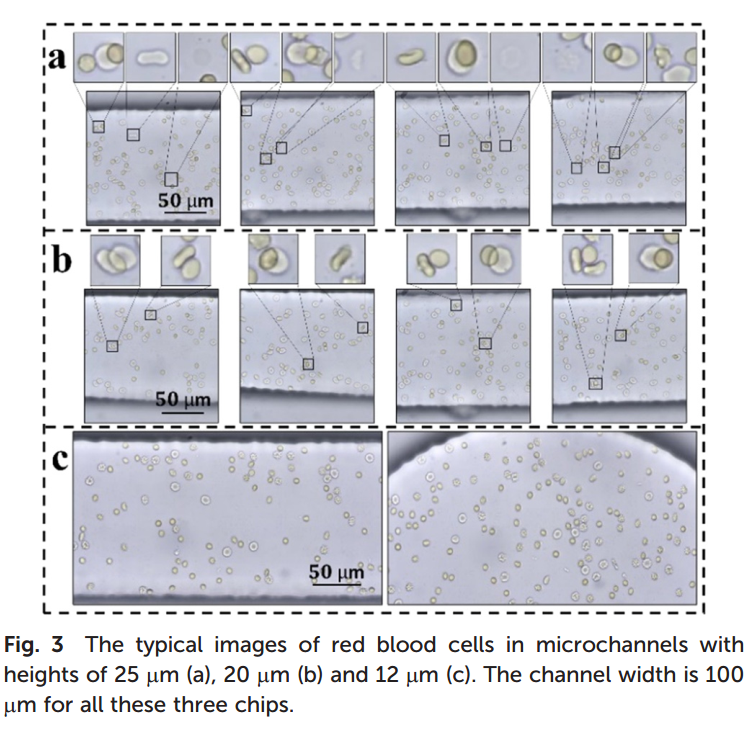
图1红细胞在高度分别为25 μm(a)、20 μm(B)和12 μm(c)的微通道中的典型图像。三种芯片的通道宽度均为100 μm
2.不同骨干网络对模型性能的影响显著。CSPdarkNet、GhostNet、VGG19及MobileNet分别作为骨干网络进行训练和验证。训练过程中,根据不同训练轮次(epoch)绘制训练损失收敛曲线(图2)。结果表明,相较于其他骨干网络,GhostNet在训练后期(31–60轮)表现出最稳定的收敛趋势,且训练与验证之间的差异最小,显示其在模型中适应性最佳。因此,后续对象检测模型的训练选用GhostNet作为骨干网络,以优化红细胞识别和分类效果。
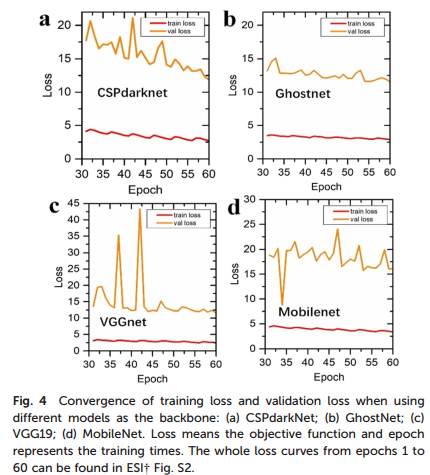
图2 不同骨干网络模型下训练损失和验证损失的收敛情况:(a)CSPdarkNet;(B)GhostNet;(c)VGG 19;(d)MobileNet。Loss表示目标函数,epoch表示训练时间。
3.红细胞识别实验显示,当目标检测模型阈值(score_threshold)较低(0.1–0.2)时,所有红细胞均被识别,但同一细胞可能被错误分类到多个亚组(红色箭头,图3a、3b);阈值为0.3时,图像出现少量未识别红细胞(黑色箭头),多亚组分类情况明显减少(图5c);阈值提高至0.4–0.5时,绝大多数红细胞可正确归入单一亚组(图5d、5e),但阈值过高(0.6)会导致部分细胞未被识别(图5f)。结果表明,红细胞亚组多且特征差异细微,仅通过调整阈值难以同时实现完整识别与准确分类,提示需优化识别策略以确保血液质量评估的精确性。
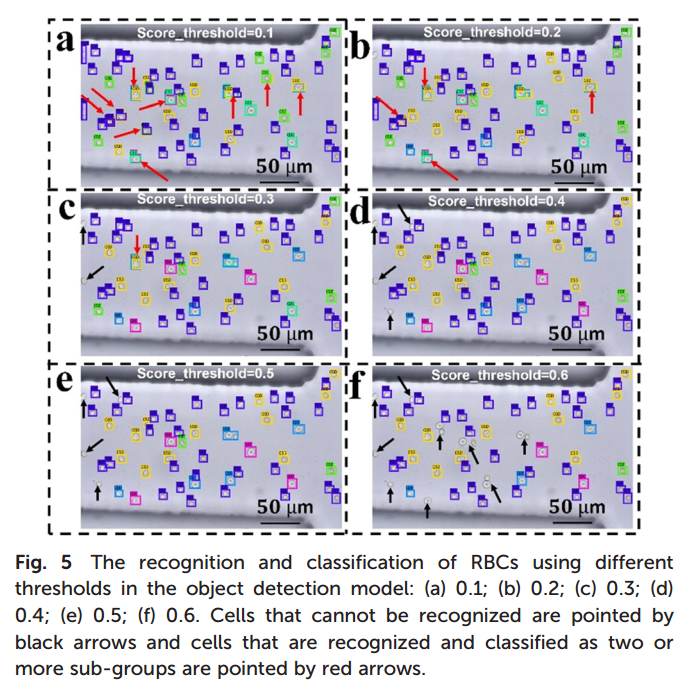
图3在不同置信度阈值下目标检测模型对红细胞的识别与分类结果:(a)0.1;(B)0.2;(c)0.3;(d)0.4;(e)0.5;(f)0.6。黑色箭头指示未被识别的细胞,红色箭头指示被识别并分类为两个或多个亚组的细胞。
4.为实现红细胞(RBCs)的完整识别与准确分类,对目标检测模型进行了改进。首先,将识别阈值设为0.1,以确保所有细胞均被识别。在此条件下,大量红细胞被分类到多个具有不同置信度的亚群中,置信度代表其被判定为某一亚群的概率。随后,对重复识别的细胞按照置信度进行筛选,仅保留置信度最高的分类结果。经过改进模型处理后,如图4所示,所有红细胞均被识别并正确分类为单一亚群,表明改进后的目标检测模型能够根据红细胞的形态差异,实现多细胞的高效识别与准确分类。
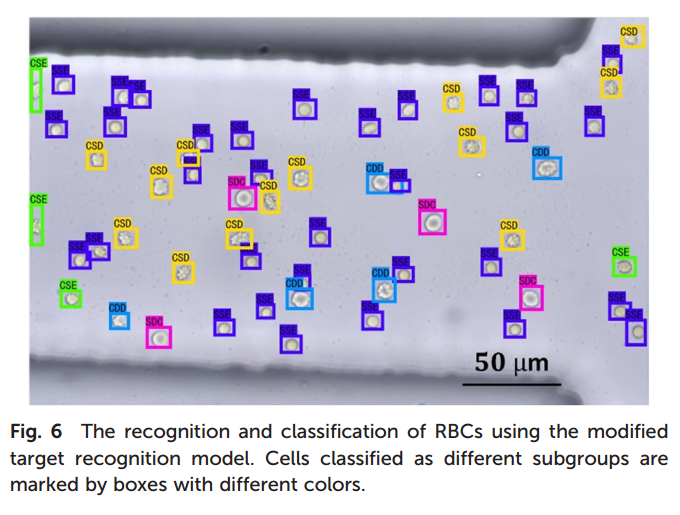
图4 利用改进的目标识别模型对红细胞进行识别和分类。不同亚群的细胞用不同颜色的方框标记
5.基于人工标注红细胞数据集的目标检测模型在多亚群分类中表现良好(图5)。引入平均精度(Average Precision, AP)作为综合指标,六种亚群的AP值分别为86.5%(SDC)、59.09%(CDC)、95.76%(CDD)、94.74%(CSD)、99.58%(CSE)和99.77%(SSE),整体平均精度(mAP)为89.24%。其中,CDC识别精度最低,主要因其膜皱褶特征与SDC相似;SSE因球形特征明显而识别率最高。
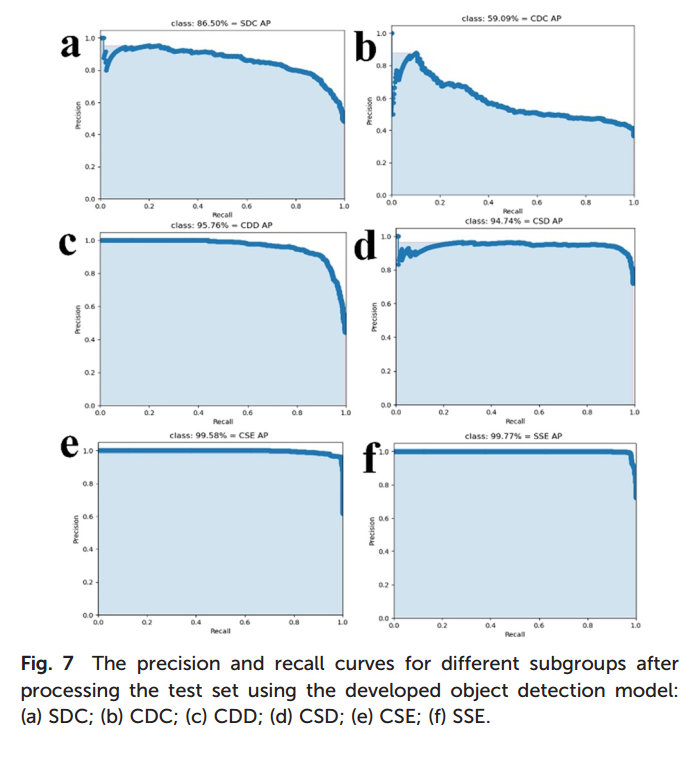
图5 使用开发的对象检测模型处理测试集后不同亚组的精确度和召回率曲线:(a)光滑盘状细胞(SDC);(B)皱缩盘状细胞(CDC);(c)皱缩圆盘状细胞(CDD);(d)皱缩球形细胞(CSD);(e)皱缩球状细胞(CSE);(f)光滑球状细胞(SSE)
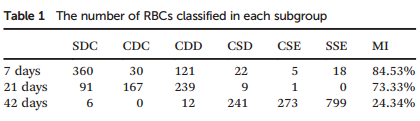
6.不同储存时间的全血样本中红细胞形态分布存在显著差异(图6)。7天储存组以正常双凹圆盘状红细胞(SDC,红框)为主;储存至21天后,部分细胞转变为皱缩盘状(CDC,绿框)和皱缩圆盘状(CDD,蓝框);而至42天时,细胞进一步细胞进一步转变为皱缩球形(CSD)、皱缩球状(CSE) 和 光滑球状(SSE)。模型在不同光照与背景条件下均能准确识别各亚群细胞,显示出良好的适应性与稳定性。根据红细胞形态指数(MI)计算,7天、21天及42天样本的MI分别为84.53%、73.33%和24.34%,提示血液质量随储存时间延长而逐渐下降。

图6 红细胞识别分类后不同血液样本的典型图像:(a)保存7天的样本;(B)保存21天的样本;(c)保存42天的样本
表1 每个亚组中分类的RBC数量
结论
基于本研究开发的微流控结合深度学习的方法,可以实现红细胞(RBCs)的高效、无标记识别与分类。通过设计低高度微通道,使盘状红细胞在同一方式下流动并获取正视图,最大程度减少细胞间视角差异。本研究构建的目标检测模型能够准确区分各亚群,且在整个视野中同时识别与分类所有红细胞,显著提升图像处理效率。通过计算形态学指标(MI)对不同储存时间的血样进行评价,可有效反映血液质量。
参考文献
Yang Y, He H, Wang J, Chen L, Xu Y, Ge C, Li S. Blood quality evaluation via on-chip classification of cell morphology using a deep learning algorithm. Lab Chip. 2023 Apr 12;23(8):2113-2121. doi: 10.1039/d2lc01078j.
老年人髋部骨折围手术期输血风险预测机器学习模型的开发与验证
编译者:王育 审校者:黄远帅
一、背景
髋部骨折是骨质疏松性骨折中后果最严重的类型,具有高发病率与高死亡率特征。2019年全球髋部骨折病例数约1420万,年龄标化发病率达每10万人182例。由于术前贫血或手术失血,髋部骨折患者常需在围手术期输注红细胞制品。尽管存在争议,但大量研究证实,围手术期使用血液制品与多种不良事件相关。若能在患者入院早期识别围手术期输血高风险人群,并实施患者血液管理(Patient Blood Management, PBM),可显著降低输血需求,为避免输血、改善患者预后创造治疗条件。机器学习(Machine Learning, ML)算法作为人工智能的重要分支,可通过学习输入数据实现预测或分类功能,其预测模型已应用于骨科手术多个领域。然而,截至目前,尚未有研究将其用于髋部骨折围手术期输血预测。本研究旨在通过分析患者入院数据,筛选围手术期输血相关早期风险因素,利用机器学习算法构建预测模型,实现患者入院早期高风险人群的识别。
二、主要结果
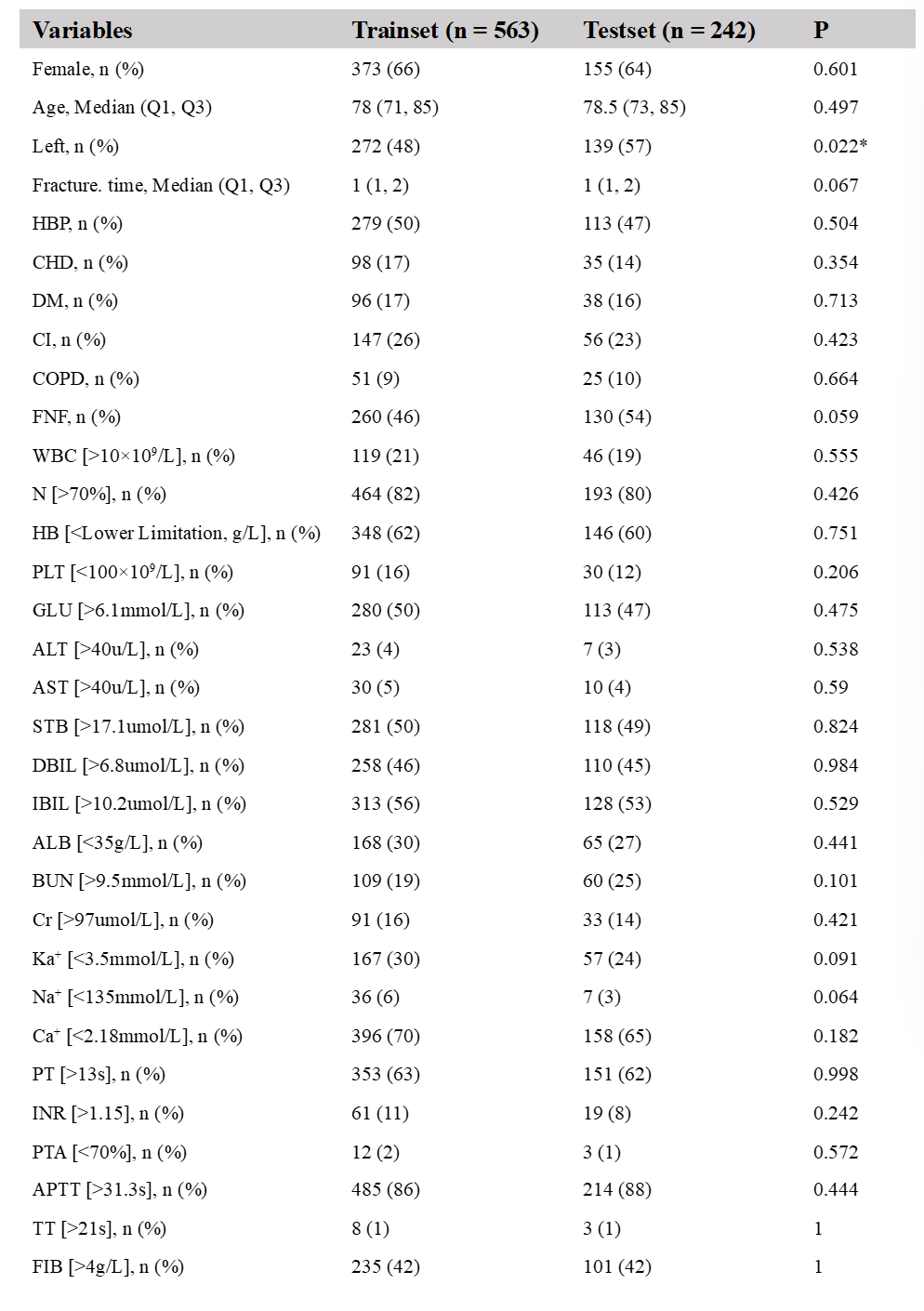
1.本研究最终纳入2016年5月至2022年11月某大学附属医院805例髋部骨折患者,其中306例(38.01%)在围手术期接受输血。所有患者按7:3比例随机分为训练集(563例)和验证集(242例),两组基线信息无显著差异(表1)。
表1 训练集和验证集的特征
2. 研究初始提取32项患者入院24小时内的变量信息(表2),经LASSO回归筛选(避免变量多重共线性),最终确定8个预测模型核心特征:年龄、骨折时间、股骨颈骨折(FNF)、血红蛋白(HB)、白蛋白(ALB)、肌酐(Cr)、钙离子(Ca?)、活化部分凝血活酶时间(APTT),筛选过程中lambda值取lambda.1se(0.04265)(图2)。
表2 训练集患者的特征
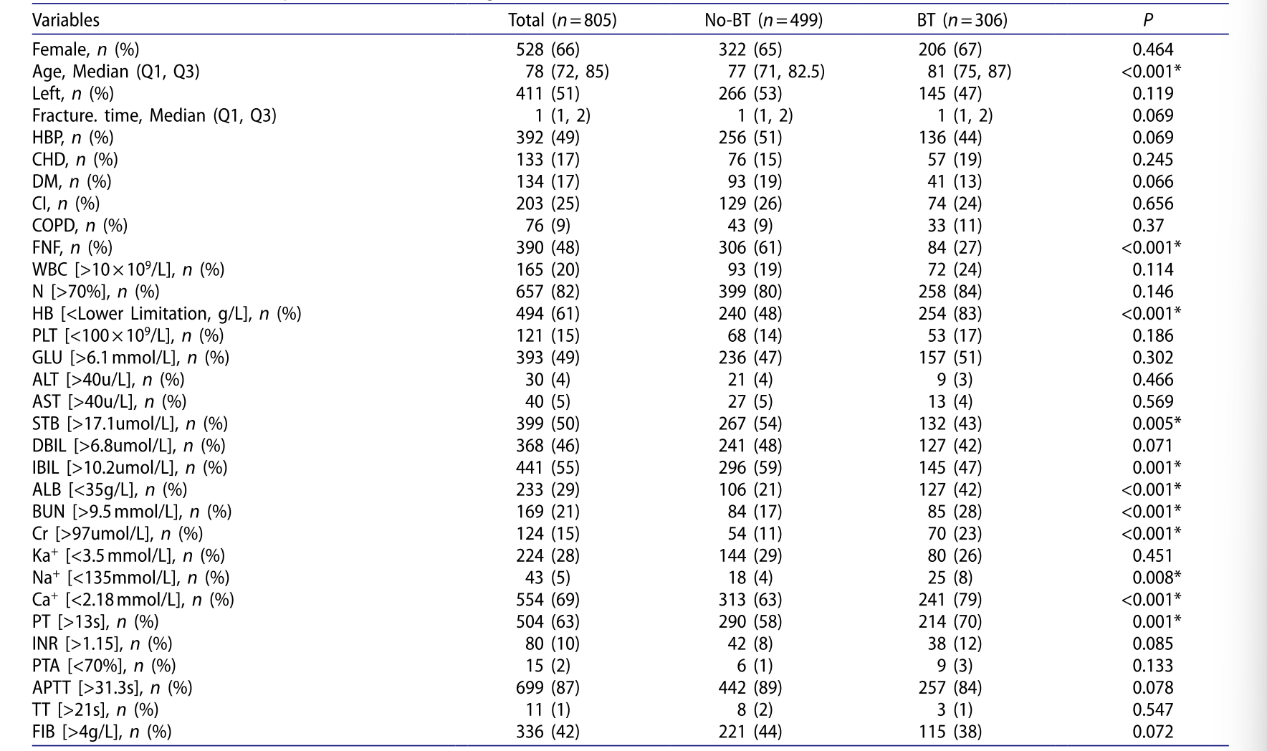
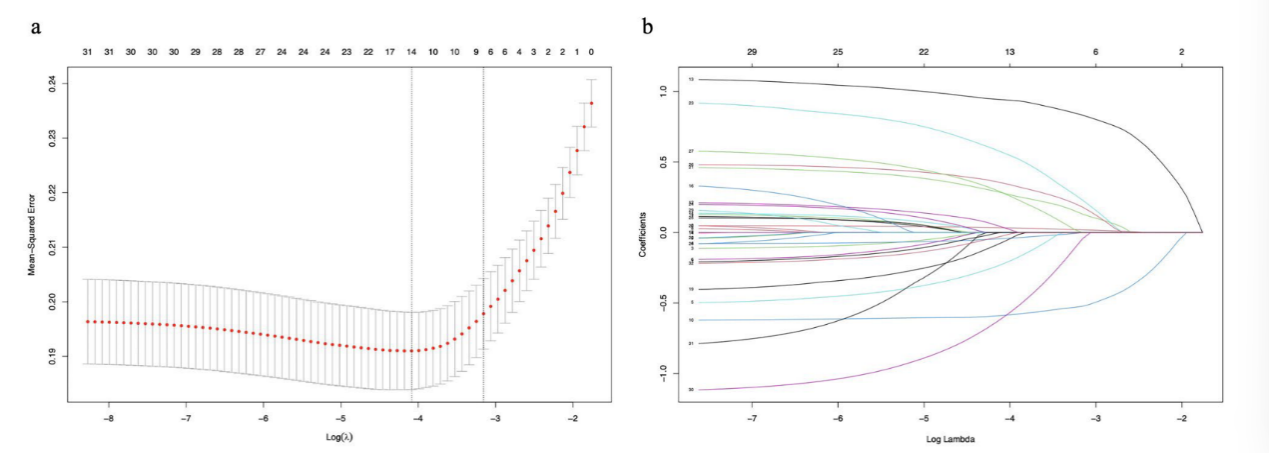
图2 采用LASSO回归分析筛选出可能的危险因素
3. 采用分类回归树(CART)、梯度提升机(GBM)、k近邻(KNN)、逻辑回归(LR)、神经网络(NNet)、随机森林(RF)、支持向量机(SVM)、极端梯度提升(XGBoost)8种机器学习算法构建预测模型,通过10次10折交叉验证重采样评估性能,各算法所构建的评估结果如表3。其中马修斯相关系数(MCC):训练集中XGBoost算法MCC为0.828,验证集达0.939,显著高于其他算法(训练集其他算法MCC 0.438-0.715,验证集0.406-0.843),且MCC值均>0.7,表明预测性能良好(表3);ROC曲线下面积(AUC):XGBoost算法在训练集AUC为0.982(95%置信区间:0.974-0.989),验证集达0.997(95% 置信区间:0.955-1),在所有算法中最优(表3,图3a、3b);其他指标:XGBoost算法在准确率(ACC)、灵敏度(SEN)、特异度(SPE)、F1分数上均表现最优,训练集与验证集Kappa值分别为0.826、0.939,一致性极佳;布里尔分数分别为0.059、0.027,均接近0,总体性能优异;决策曲线分析(DCA)显示,其在宽阈值范围内净收益高于“全干预”或“无干预”策略(表3,图3c-f)。
表3各算法所构建模型的评估指标
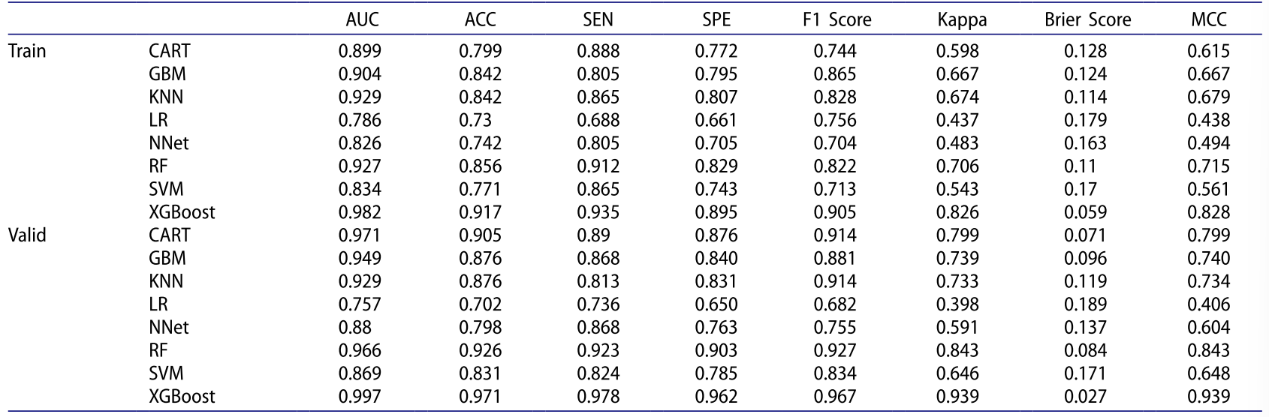
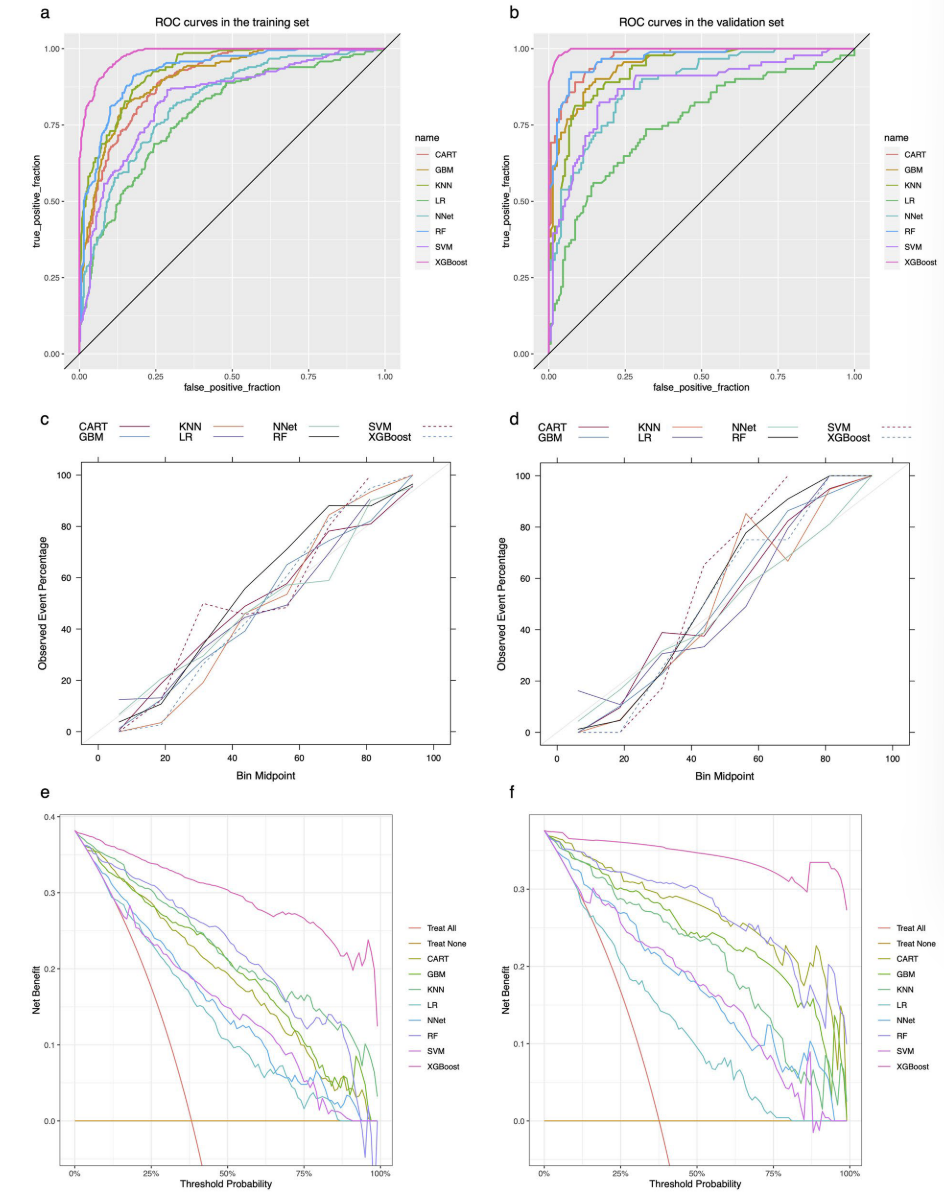
图3 各模型在训练集和验证集中的ROC曲线、校准曲线及DCA曲线
4.特征重要性:通过SHAP值分析发现,年龄、血红蛋白(HB)、股骨颈骨折(FNF)是老年人髋部骨折围手术期输血的前三大重要特征(图4)。
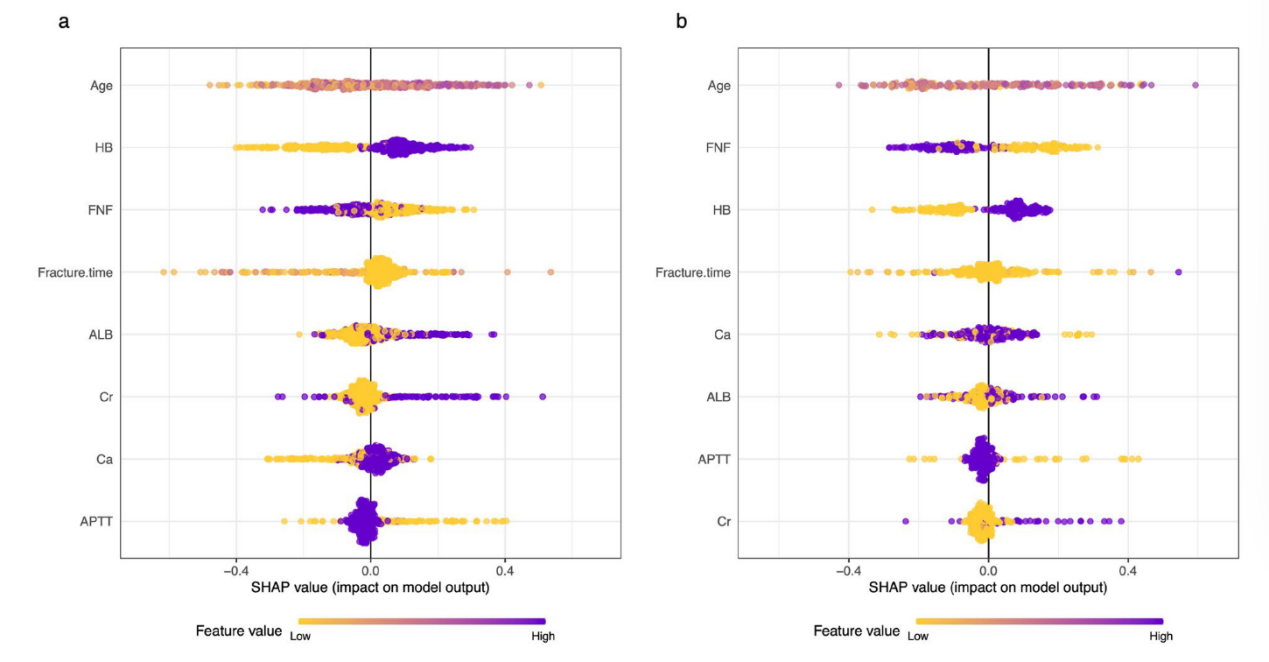
图4 基于极端梯度提升(XGBoost)算法构建模型的SHAP值总结图
5.所有模型布里尔分数均<0.25,表明总体性能均满足临床需求,但XGBoost算法构建的模型在各项评估指标中均表现最优。
三、结论
本研究构建了老年人髋部骨折围手术期输血风险预测模型,经LASSO回归筛选出年龄、骨折时间、股骨颈骨折、血红蛋白、白蛋白、肌酐、钙离子、活化部分凝血活酶时间8项有效预测特征;在8种机器学习算法中,XGBoost模型性能最优,训练集与验证集MCC分别为0.828、0.939,AUC分别为0.982、0.997,且校准度与临床实用性良好,可在患者入院早期识别输血高风险人群并纳入PBM计划以降低输血需求与风险。同时研究指出,数据单中心、缺乏外部验证、回顾性设计及样本量不足可能影响模型泛化性与结论稳健性,未来需通过多中心前瞻性研究进一步验证优化模型。
四、文献来源
Guo J, He Q, Li Y. Development and validation of machine learning models to predict perioperative transfusion risk for hip fractures in the elderly. Ann Med. 2024 Dec;56(1):2357225. doi: 10.1080/07853890.2024.2357225. Epub 2024 Jun 20. PMID: 38902847; PMCID: PMC11191839.
