- 中国科学论文统计源期刊
- 中国科技核心期刊
- 美国化学文摘(CA)来源期刊
- 日本科学技术振兴机构数据库(JST)
多中心外科手术围术期用血预测机器学习模型的研究进展
本期《输血医学新进展》聚焦于多中心外科手术围术期用血预测机器学习模型的研究进展。通过梳理三篇代表性研究,分别涵盖二尖瓣手术、体外循环心脏外科手术及脊柱外科手术人群,系统呈现了基于多中心数据构建与验证的输血预测模型的发展现状。相关研究不仅通过多模型比较、跨中心外部验证及可解释性分析,显著提升了模型的预测性能与临床可信度,也推动输血风险评估从传统的“术中/术后被动反应”向“术前主动预测”转变。总体来看,这些研究成果为实现个体化患者血液管理(PBM)、优化血液资源配置及降低输血相关不良结局提供了有力支撑,进一步推动围术期输血决策向精准化与规范化方向发展。
机器学习用于预测二尖瓣手术期间或术后输血风险:一项多中心回顾性队列研究
编译者:黄先俊 审校者:黄远帅
背景
瓣膜性心脏病是全球心血管疾病发病率和死亡率的主要原因,二尖瓣疾病占瓣膜性心脏病致死病例的15%,手术可显著降低死亡率,但围手术期易出现凝血障碍和失血,需RBC输注维持血容量和氧供。目前临床输血决策多依赖血红蛋白水平和贫血症状,缺乏明确指南,且全球献血率下降加剧血资源紧张。既往研究多依赖术中或术后变量(如体外循环时间),限制术前风险干预。机器学习在处理复杂数据方面优于传统统计方法,已成功应用于肝移植和膝关节置换术的输血预测,故本研究假设通过术前数据构建机器学习模型可预测二尖瓣手术患者的RBC输注需求,以优化输血管理。
主要研究结果
1. 共纳入1477例患者,60.87%为女性,中位年龄53岁,73.3%接受机械二尖瓣置换术,862例(58.4%)接受RBC输注。
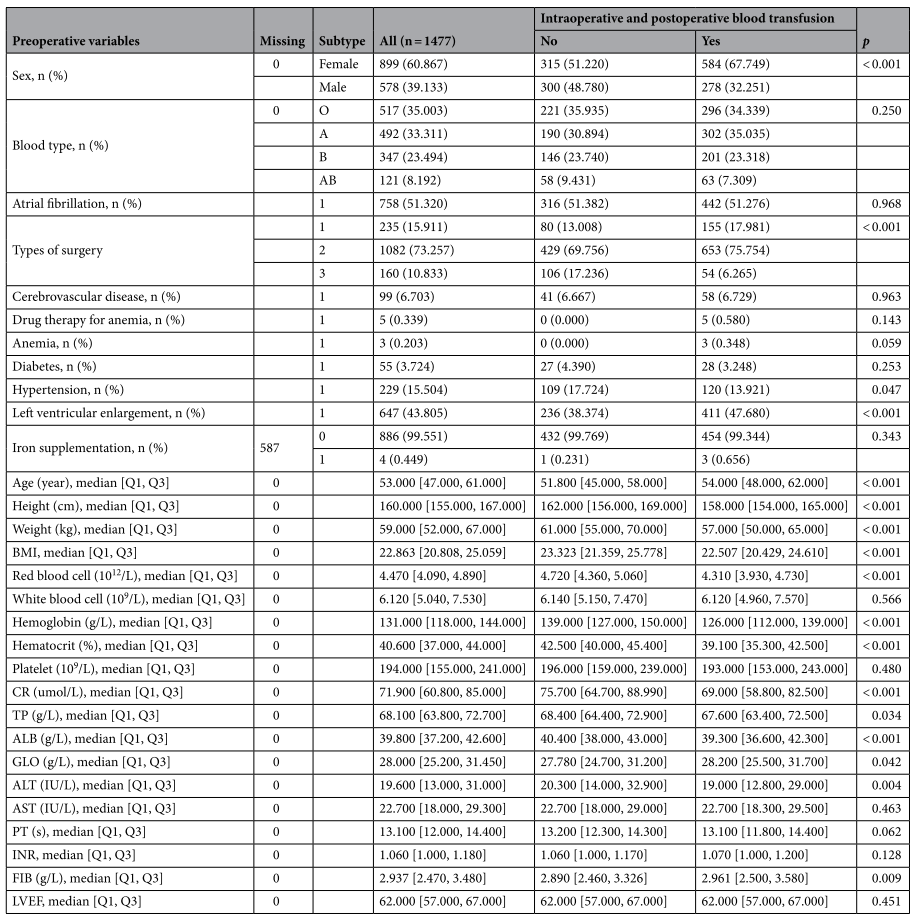
表1 术前信息
2. 最大相关性和最小冗余度算法(mRM)筛选出10项关键术前变量:红细胞压积、红细胞计数、体重、BMI、纤维蛋白原、血红蛋白、身高、年龄、左心室扩张、性别。
3. LightGBM模型性能最优,训练集AUC 0.935、准确率86.3%,验证集AUC 0.734,测试集AUC 0.722,前瞻性数据集准确率74.2%。
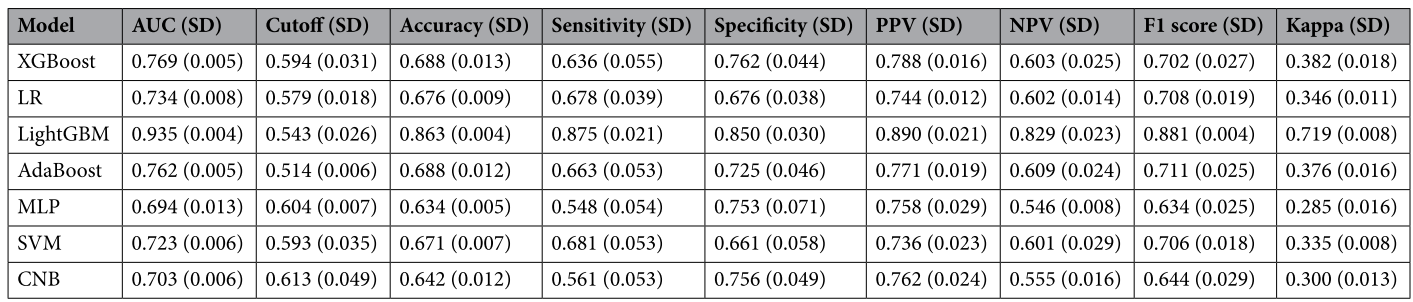
表2 机器学习模型在训练集中的表现
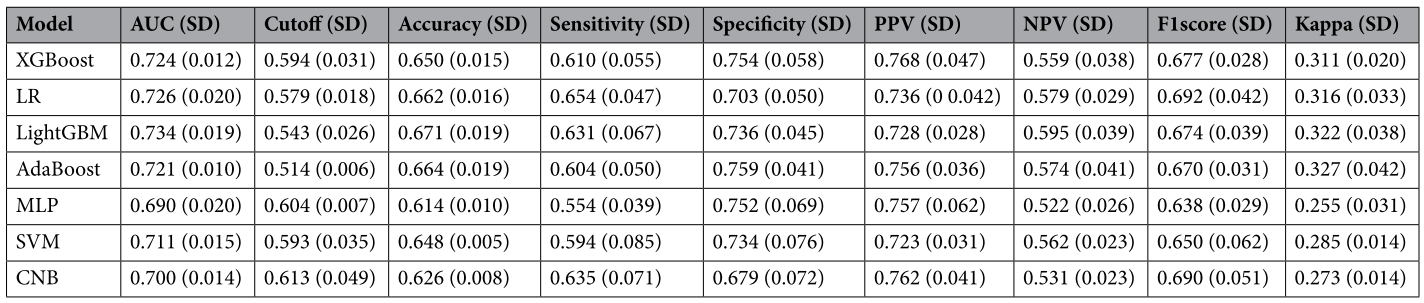
表3 机器学习模型在验证集中的表现
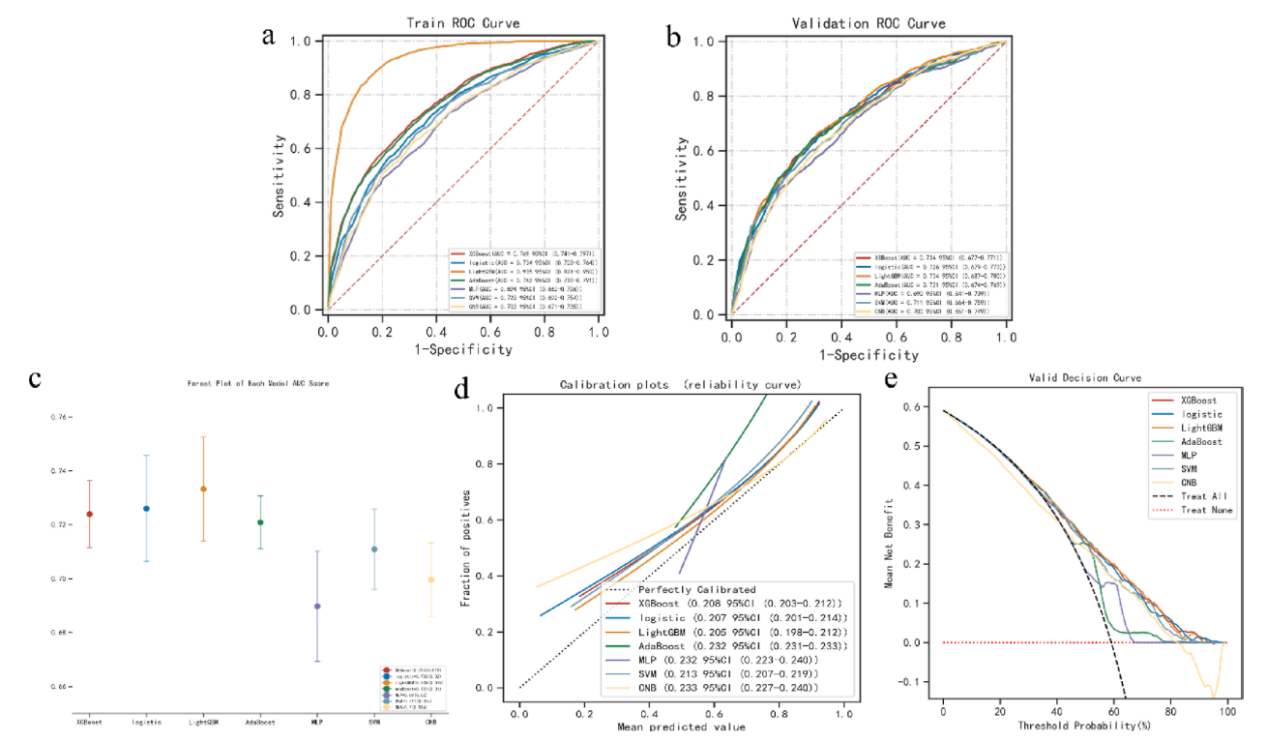
图1 多个模型的比较。图(A)显示训练集中多个模型的受试者工作特性曲线(ROC)下的面积(AUC)。ROC曲线显示了不同阈值设置下的敏感性(真阳性率)和特异性(假阳性率)之间的权衡。AUC值越高,模型的整体性能越好,因为它反映了模型在所有阈值上正确区分正面和负面结果的能力。(B)显示验证集中多个模型的AUC。(C)显示了多个模型的AUC分数的森林图,提供了性能指标的直观表示。(D)为多个模型的校准图。一个校准良好的模型将有一条接近对角线的校准曲线,表示完美的校准。括号中的值表示每个模型的Brier分数及其95%的可信区间。Brier分数评估预测概率的准确性;分数越低表示模型性能越好。(E)多种模型的临床决策曲线。这个子图有助于评估模型在临床决策中的实用性。临床决策曲线显示了不同阈值选择的利与弊之间的权衡,为该模型在临床环境中的实际应用提供了见解。
4. SHAP分析显示红细胞压积是影响输血风险的最关键变量,女性、低BMI、高龄、左心室扩张、贫血等因素与高输血风险相关。
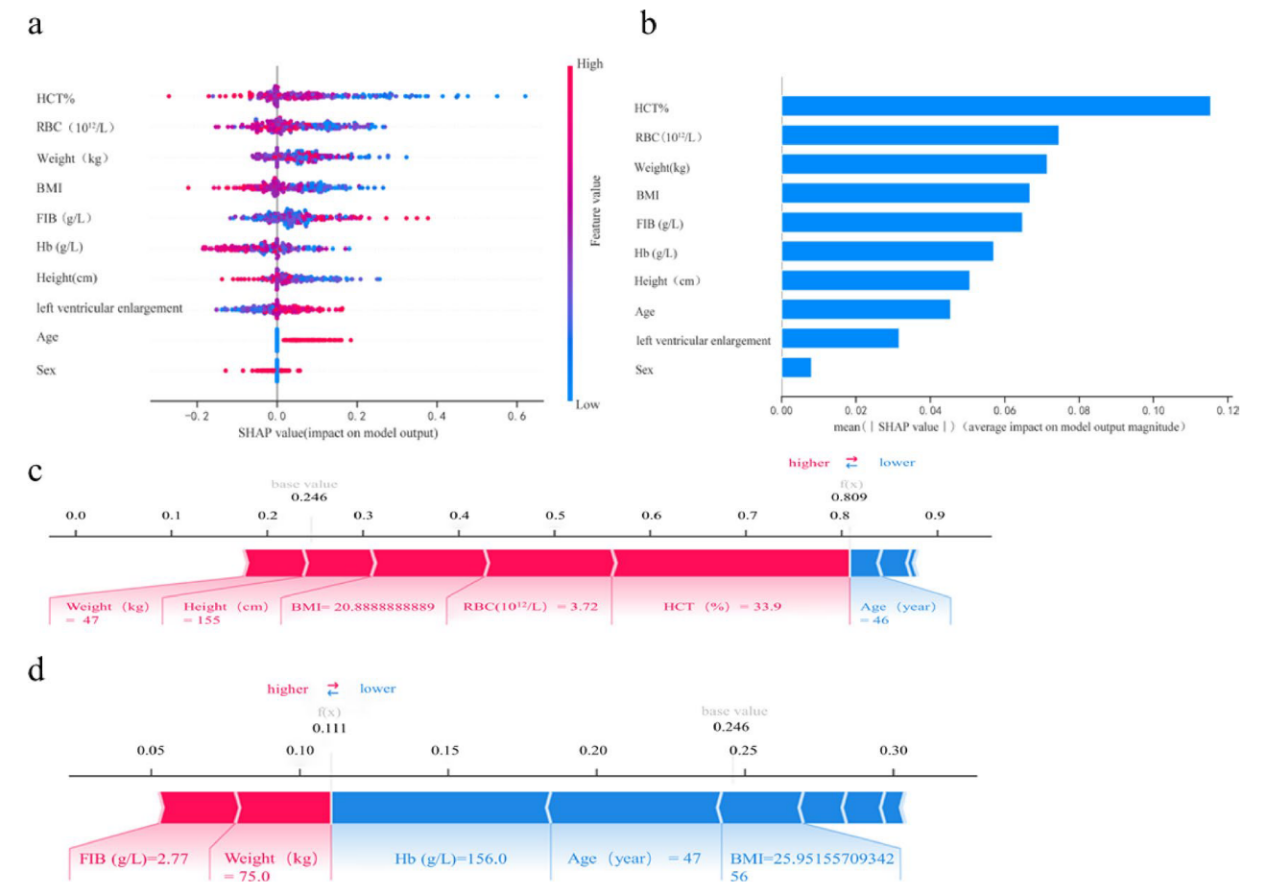
图2 模型的可解释性。图(A)提供了LightGBM模型的前10个变量的Shap(Shapley附加解释)摘要图。这张图显示了整个队列的信息,每个点代表一个单独的患者。颜色与变量的值有关,蓝色表示较低的值,而红色表示较高的值。Shap值表示二尖瓣手术期间和术后输血的预期可能性,它被绘制在图表的水平轴上。变量对结果影响的大小与其在水平坐标中的绝对值成正比;越显著的值表示影响的程度越大。例如,较低的输血可能性与较高的血红蛋白值相关。(B)每个变量对结果的贡献排名,红细胞压积被确定为最有影响的因素。(C)和(D)说明每个变量如何影响结果的力量图。红色表示正面贡献,蓝色表示负面贡献。
结论
LightGBM模型是预测二尖瓣手术患者RBC输注需求的最优机器学习模型,其高准确性有助于临床提前识别高风险患者,优化输血管理决策。10项关键术前变量(如红细胞压积、血红蛋白等)对预测起主要作用。机器学习预测模型有望为临床提供精准的术前输血风险预测工具,帮助提前制定输血管理策略,减少不必要输血和血资源浪费,降低输血相关不良结局,推动患者血液管理(PBM)的个体化实施。
参考文献
Wang Y, Liu L, Fan K, et al. Machine learning for the prediction of blood transfusion risk during or after mitral valve surgery: a multicenter retrospective cohort study. Sci Rep. 2025 Sep 5;15(1):32380. doi: 10.1038/s41598-025-16924-3. PMID: 40913052; PMCID: PMC12413438.
心脏手术围术期红细胞输注机器学习预测模型的开发与验证
编译者:蔡智 审校者:黄远帅
背景:
输血是心脏外科围术期中不可或缺的关键干预措施,尤其在体外循环手术中应用广泛。然而,尽管红细胞输注有助于维持组织氧供,其相关风险同样显著,包括感染率、死亡率及医疗负担的增加。因此,在保障患者安全的前提下减少不必要输血,已成为临床亟需解决的问题。研究表明,围术期输血受多因素共同影响。若能及早识别高风险患者,并实施个体化干预策略,将有助于优化资源配置并改善预后。因此,构建精准、稳定的输血风险预测模型具有重要临床意义。随着机器学习的发展,其在处理复杂非线性关系方面展现出优于传统方法的潜力。但目前相关研究仍有限,且多缺乏外部验证,泛化能力不足。基于此,本研究拟开发并验证多种预测模型,以提升体外循环心脏手术中红细胞输注风险评估的准确性与临床应用价值。
主要结果
1.本研究基于阜外医院体外循环心脏手术患者数据,按8:2比例划分训练集(结合交叉验证)和测试集进行模型开发与内部评估;随后纳入国内另外三家中心数据及MIMIC-IV国际数据库(按70岁分层)开展跨地域、跨人群的外部验证,并进一步完成模型可解释性分析。
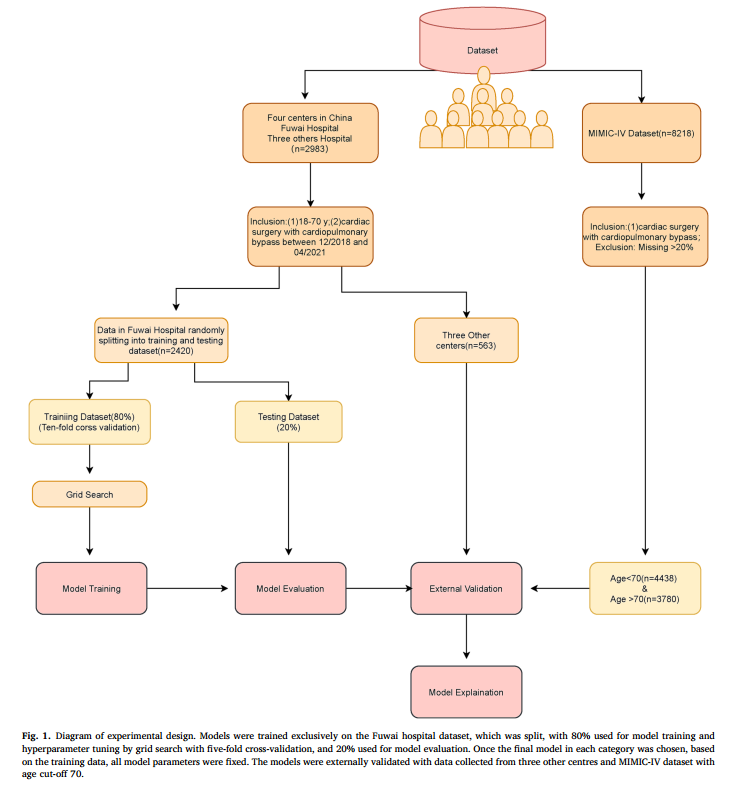
图1.实验设计图
2.来自北京阜外医院共2420例符合条件的患者被纳入模型开发,其中1936例用于训练集,484例用于测试集。此外,来自中国其他三个中心的563例患者以及MIMIC-IV数据集的8218例患者被纳入外部验证。依据OPTIMAL试验中与年龄相关的分层标准,将MIMIC-IV数据集划分为年龄≤70岁和>70岁两组。患者人口学特征见表1。围术期红细胞输注发生率分别为:开发队列21.4%,中国多中心外部验证队列35.2%,MIMIC-IV数据集40.6%(其中≤70岁组31.0%,>70岁组51.6%)。
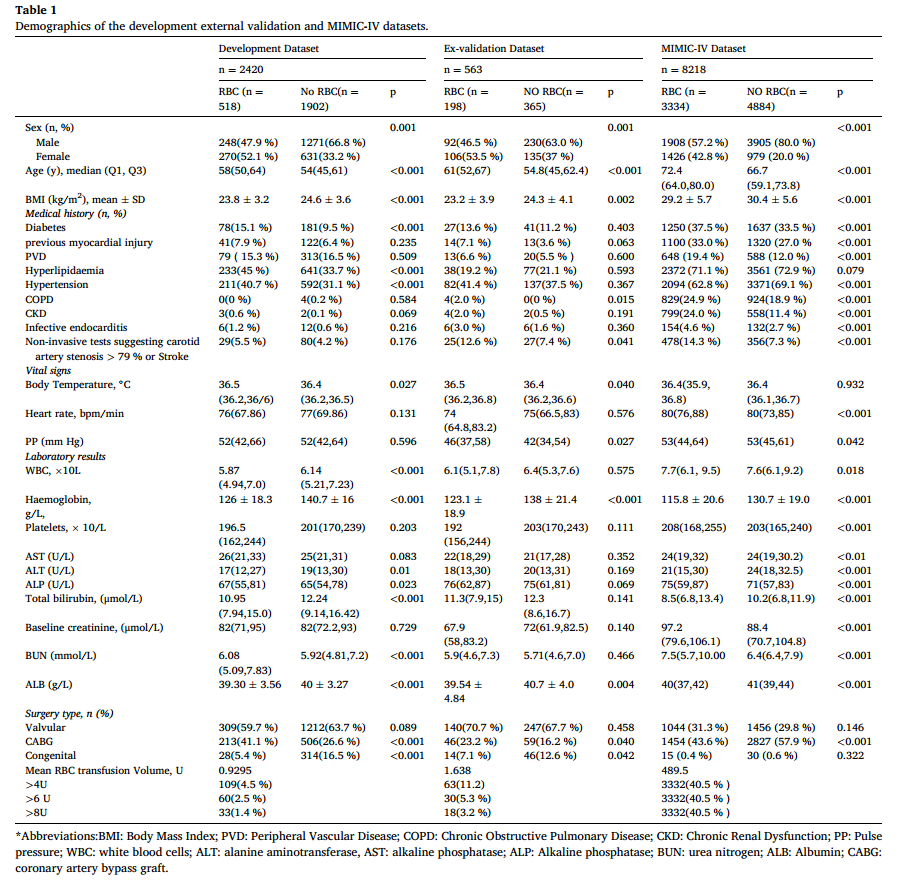
表1开发外部验证和MIMIC-IV数据集的人口统计学
3.在内部测试集中,LR(0.829)、CAT(0.828)、RF(0.819)和SVM(0.806)表现出优异性能(AUROC均>0.8);EX(0.799)、AB(0.791)、XGB(0.798)、LGBM(0.789)、GB(0.781)、BAY(0.728)和KNN(0.710)表现尚可(AUROC为0.7–0.8),而DT表现较差(AUROC<0.6)。LR模型性能与CAT(0.829 vs 0.828, p=0.929)及RF(0.829 vs 0.819, p=0.451)相当。在中国多中心外部验证中,逻辑回归(0.717)、CatBoost(0.741)、随机森林(0.751)、支持向量机(0.719)、极端随机树(0.709)、AdaBoost(0.711)、XGBoost(0.742)、轻量梯度提升机(0.723)及梯度提升(0.730)均表现出可接受性能(AUROC>0.7),而朴素贝叶斯、K近邻及决策树低于0.7。进一步分析显示,逻辑回归显著劣于CatBoost(p=0.031)和随机森林(p=0.012)。在MIMIC-IV数据集中,年龄≥70岁患者中,CatBoost(0.711)和随机森林(0.713)表现稳定(AUROC>0.7),且均优于逻辑回归(p<0.001);年龄<70岁患者中,CatBoost(0.705)、随机森林(0.706)和极端随机树(0.700)同样达到可接受水平,其余模型均低于0.7。
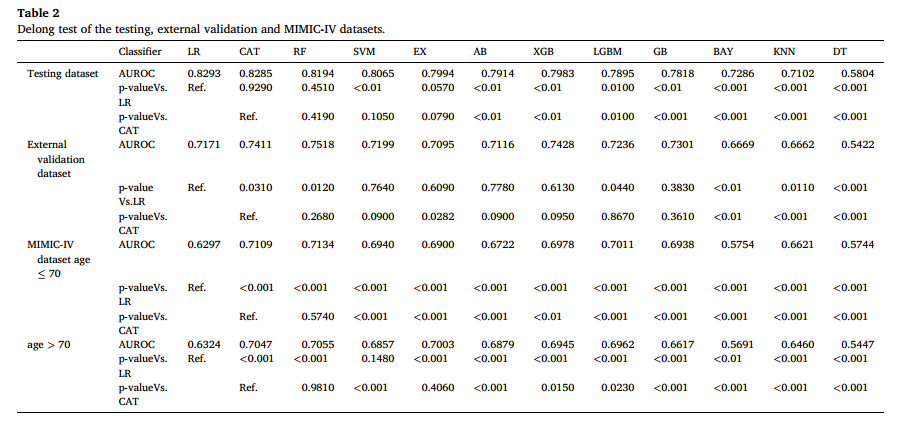
表2测试、外部验证和MIMIC-IV数据集的Delong检验
4.在内部测试集中,LR、CAT、RF、SVM、XGB和EX的AUPRC均>0.5,而KNN、DT、BAY、GB、LGBM及AB低于0.5。除朴素贝叶斯外,其余模型均具有良好的校准能力,预测概率与实际观测值一致性较高。在中国多中心外部验证中,CatBoost、随机森林及AdaBoost的AUPRC>0.6,其余模型低于0.6;除决策树和朴素贝叶斯外,其余模型均表现出良好校准度。在MIMIC-IV数据集中,年龄≥70岁患者中,CatBoost、随机森林、支持向量机及极端随机树的AUPRC>0.5;年龄<70岁患者中,CatBoost、AdaBoost及极端随机树的AUPRC接近0.7。整体而言,大多数模型均具有稳定的校准性能。
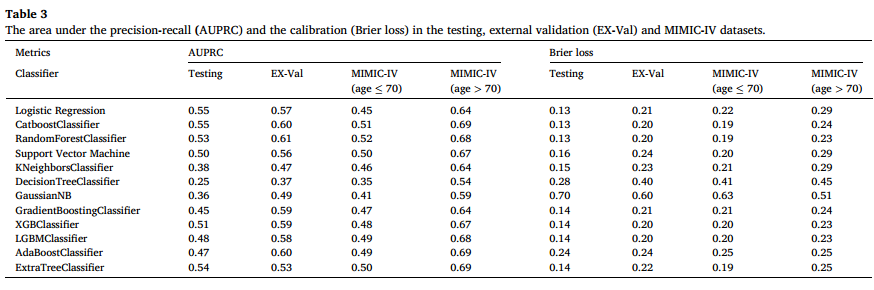
表3测试、外部验证(EX-Val)和MIMIC-IV数据集中的精确度-召回率(AUPRC)和校准(Brier损失)下的面积
5.CatBoost和随机森林模型在区分度与校准度方面均表现优异,且两者在测试集(0.828 vs 0.819,p=0.419)、外部验证集(0.741 vs 0.752,p=0.268)及MIMIC-IV数据集(年龄≤70岁:0.710 vs 0.713,p=0.574;年龄>70岁:0.705 vs 0.705,p=0.981)中的表现相当。因此,在多个数据集中对逻辑回归、CatBoost及随机森林模型进行了决策曲线分析(图2)。结果显示,在外部验证集中阈值概率<0.4时以及在MIMIC-IV数据集的整个阈值范围内,CatBoost和随机森林均获得更高净收益,优于逻辑回归模型。
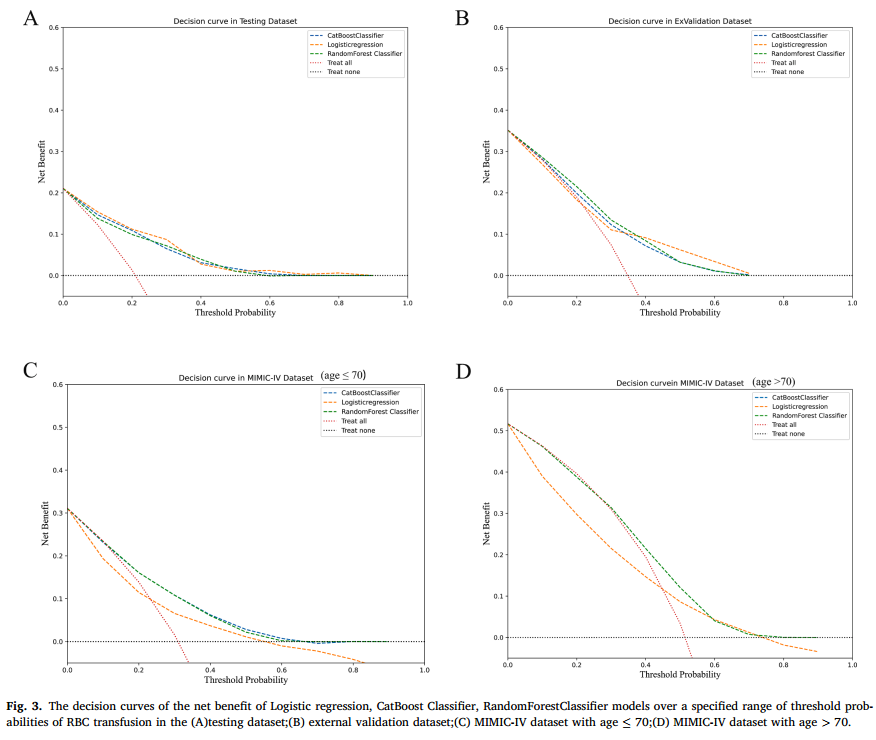
图2.在(A)测试数据集;(B)外部验证数据集;(C)年龄≤ 70岁的MIMIC-IV数据集;(D)年龄> 70岁的MIMIC-IV数据集中,Logistic回归,CatBoost分类器,RandomForestClassifier模型在红细胞输血阈值概率指定范围内的净效益决策曲线
6.采用SHAP汇总图评估各特征对模型预测的贡献,SHAP值越高表示红细胞输注风险越高。基于CatBoost模型,在测试集及外部验证集中,术前血红蛋白、年龄、体重指数、先天性手术类型及性别为前五位关键影响因素。在MIMIC-IV数据集中,前五位因素基本一致,仅以血尿素氮替代其中一项(图3)。
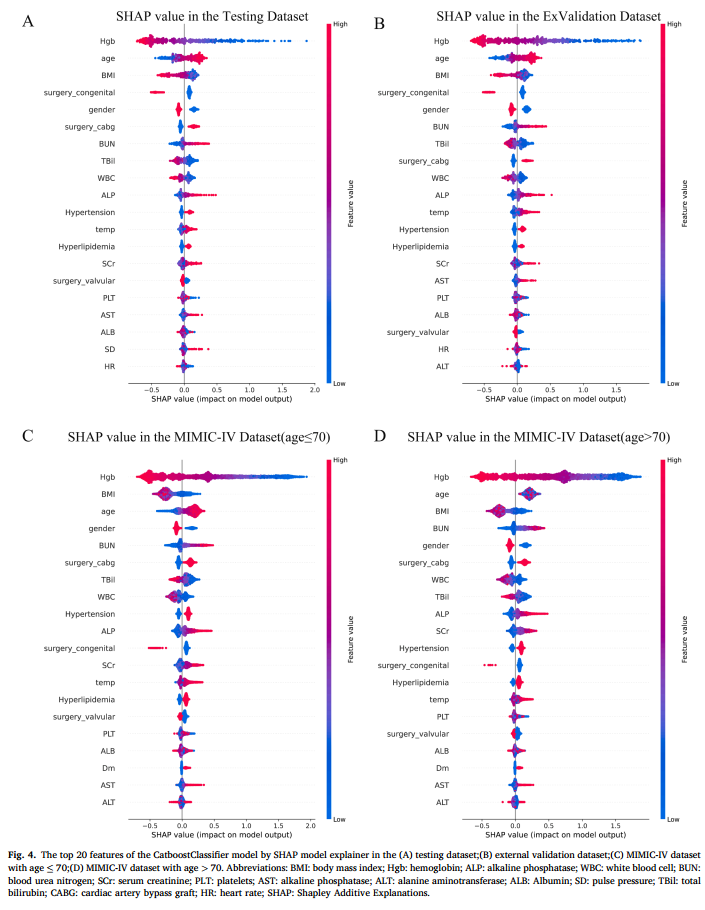
图3.在(A)测试数据集;(B)外部验证数据集;(C)年龄≤ 70岁的MIMIC-IV数据集;(D)年龄> 70岁的MIMIC-IV数据集中,SHAP模型解释器的CatboostClassifier模型的前20个特征
结论:
本研究纳入多类型体外循环心血管手术患者,并采用限制性红细胞输注策略,系统验证了机器学习算法在预测红细胞输注风险方面的良好泛化能力。值得关注的是,CatBoost和随机森林模型在不同数据集中的表现稳定,展现出较强的外部临床适用性和推广潜力。本研究为基于机器学习的输血风险评估提供了有力证据,有望提升临床决策的精准性与实用价值。
参考文献:
Li Q, Lv H, Chen Y, et al. Development and validation of a machine learning prediction model for perioperative red blood cell transfusions in cardiac surgery. Int J Med Inform. 2024 Apr;184:105343. doi: 10.1016/j.ijmedinf.2024.105343. Epub 2024 Jan 26. PMID: 38286086.
严重腰椎间盘突出症术中输血预测机器学习模型的开发与验证
编译者:黄远帅 审校者:黄远帅
背景:
输血是脊柱外科围术期管理中的关键干预措施,尤其在后路腰椎椎体间融合术(PLIF)中具有重要意义。尽管红细胞输注在维持组织氧供、保障手术安全方面发挥着重要作用,但其潜在风险同样不可忽视,包括感染风险增加、术后恢复延迟及医疗资源消耗加重等。因此,在确保患者安全的前提下减少不必要输血,已成为脊柱外科领域亟待解决的重要问题。研究表明,术中输血的发生受多种因素共同影响。若能在术前阶段识别高风险患者,并实施个体化围术期管理策略,将有助于优化血液资源配置并改善临床结局。因此,构建精准、稳定的输血风险预测模型具有重要临床价值。随着机器学习技术的发展,其在处理高维数据及复杂非线性关系方面展现出优于传统方法的潜力。然而,目前相关研究多为单中心、小样本设计,缺乏系统性的多中心验证,模型泛化能力仍有限。基于此,本研究旨在开发并验证多种机器学习模型,以提升LDH患者PLIF术中输血风险评估的准确性与临床应用价值。
主要结果:
1.本研究基于中国22家三级医院LDH患者PLIF手术数据,按照7:3比例划分训练集与测试集,并结合10折交叉验证完成模型开发与内部评估;同时设置4个独立测试集开展多中心外部验证,并进一步进行模型可解释性分析。
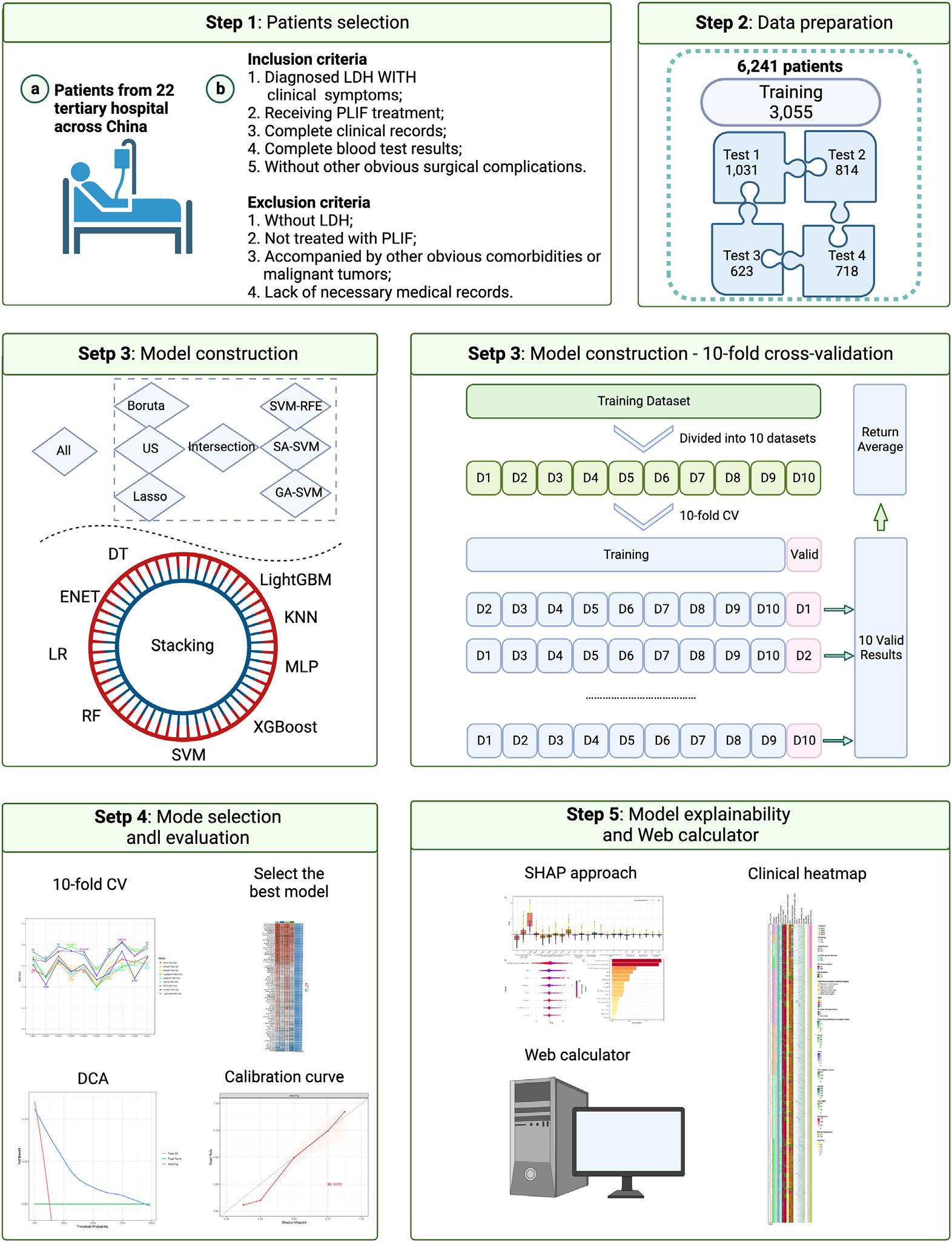
图1 研究整体流程图:研究全流程设计,涵盖患者筛选、数据准备、模型构建、模型评价、可解释性分析与临床工具开发5大核心步骤。
2.共纳入6241例符合标准的患者,其中3055例用于训练,3186例用于测试及外部验证。整体人群中,术中输血发生率为14.8%(926/6241)。患者性别分布基本均衡(男性51%,女性49%)。
3.在模型构建过程中,共评估80种“特征选择方法+算法模型”的组合。结果显示,GA-SVM联合Stacking模型表现最佳(AUC-ROC=0.886),SA-SVM联合Stacking模型次之(AUC-ROC=0.884),两者性能接近。考虑到SA-SVM+Stacking模型仅需16个特征,临床应用更为便捷,最终确定为最优模型。基础模型中,LightGBM与随机森林表现较优(AUC-ROC均为0.86),XGBoost次之(AUC-ROC=0.85)。
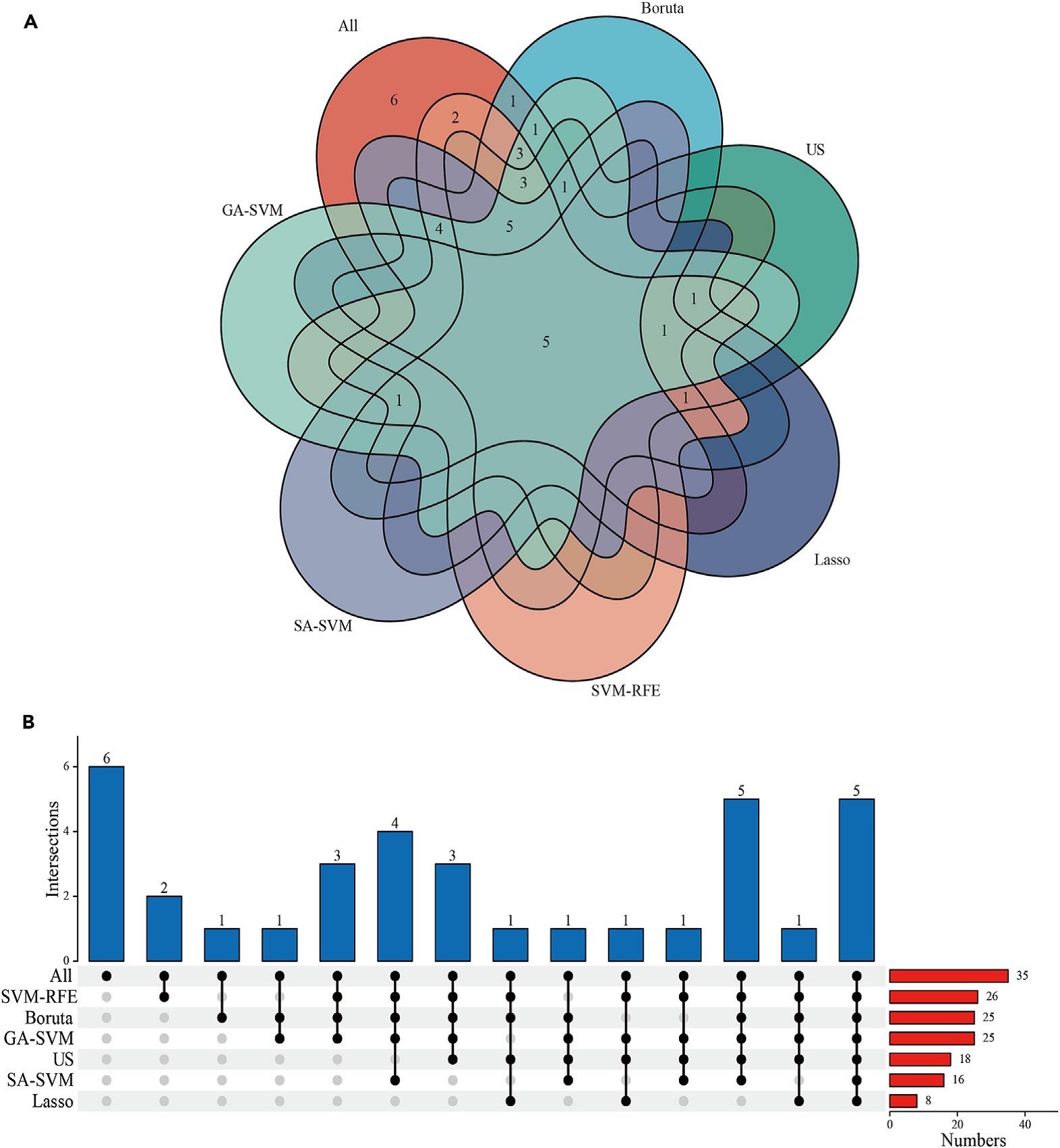
图2 特征选择结果图:(A)6种特征选择模型与原始特征的交集韦恩图;(B)各模型筛选特征详情。
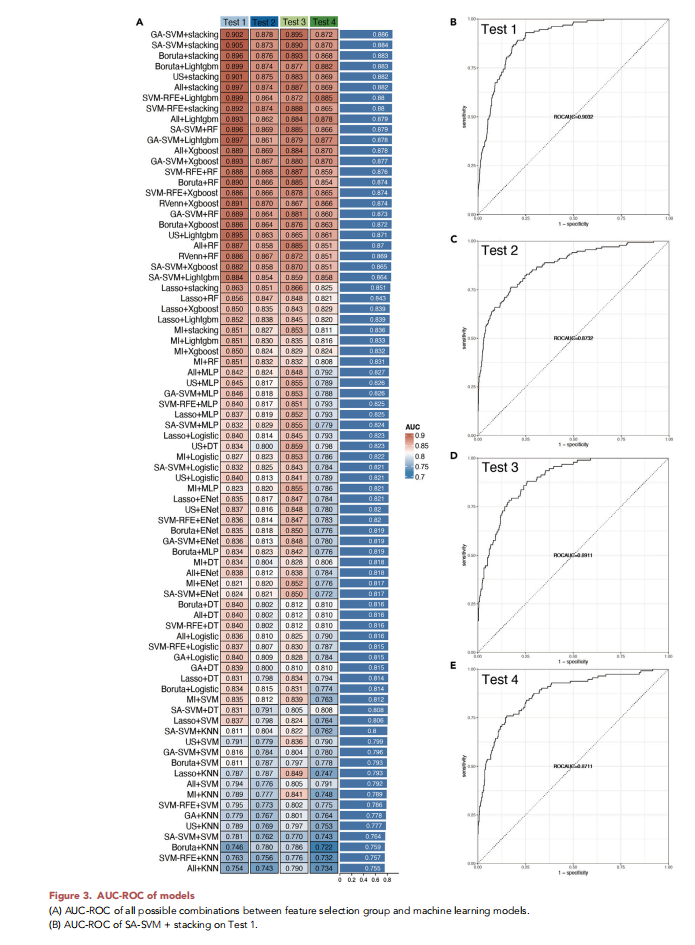
图3 模型的AUC-ROC曲线
4.在模型性能评估方面,最优模型在4个独立测试集中均表现出良好的稳定性,Brier评分均低于0.01,提示预测误差较小。校准曲线显示,大多数模型具有良好的一致性,其中最优模型在高风险区间预测值与实际发生率高度吻合,在低风险区间略有低估。
5.决策曲线分析结果显示,在临床常用阈值概率(>90%)范围内,最优模型始终优于“全部输血”及“均不输血”策略,具有更高的净获益,提示其在实际临床决策中具有重要应用价值。
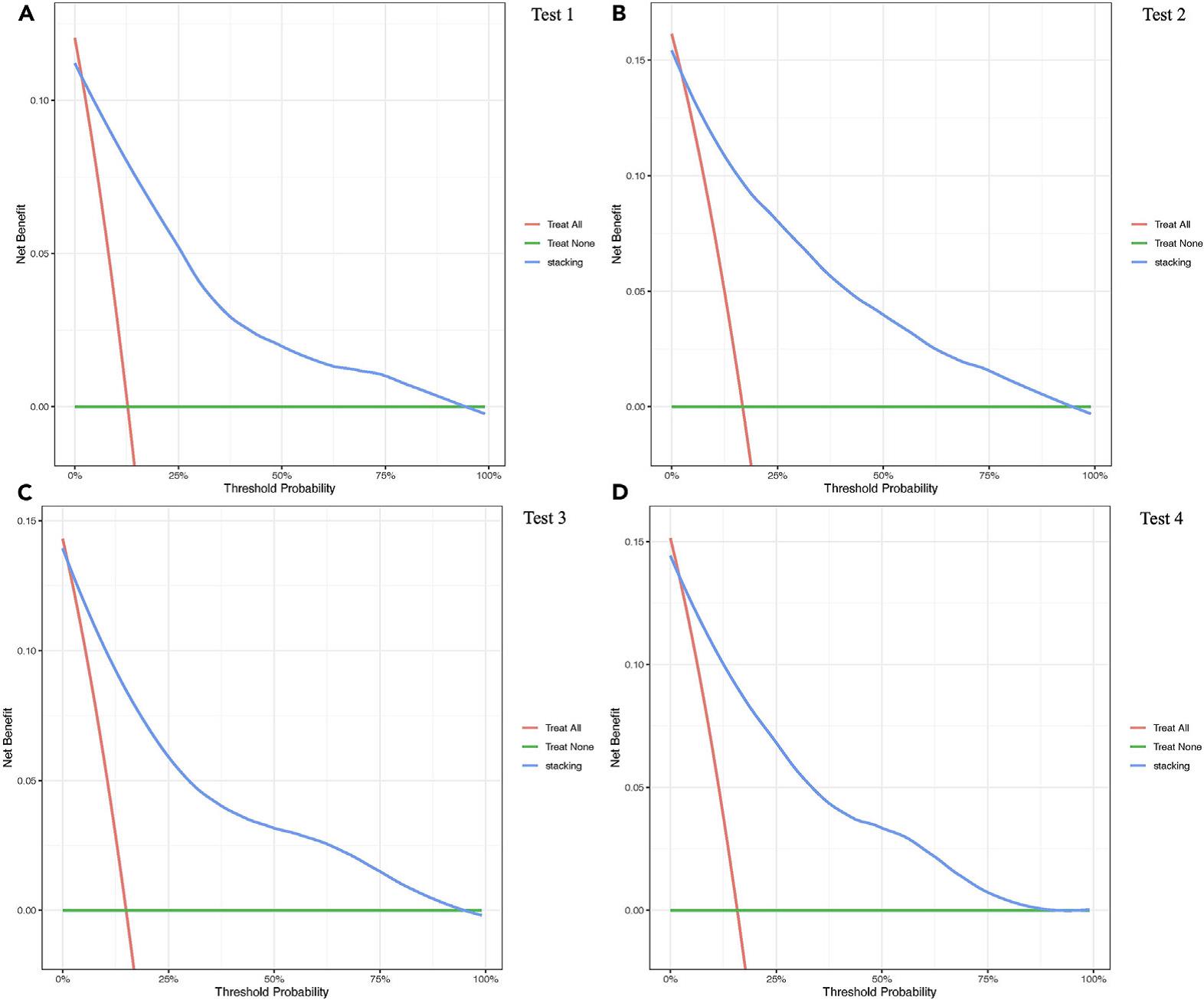
图4 最优模型决策曲线分析(DCA)图:SA-SVM+Stacking模型在4个测试集的DCA曲线,对比模型与极端决策策略的临床净获益。
6.通过SHAP方法对模型进行解释性分析,结果表明,融合节段数量、入院至手术时间、年龄及术前血红蛋白水平等为影响术中输血风险的关键因素。SHAP值越高提示输血风险越大,各变量贡献方向与临床认知一致。
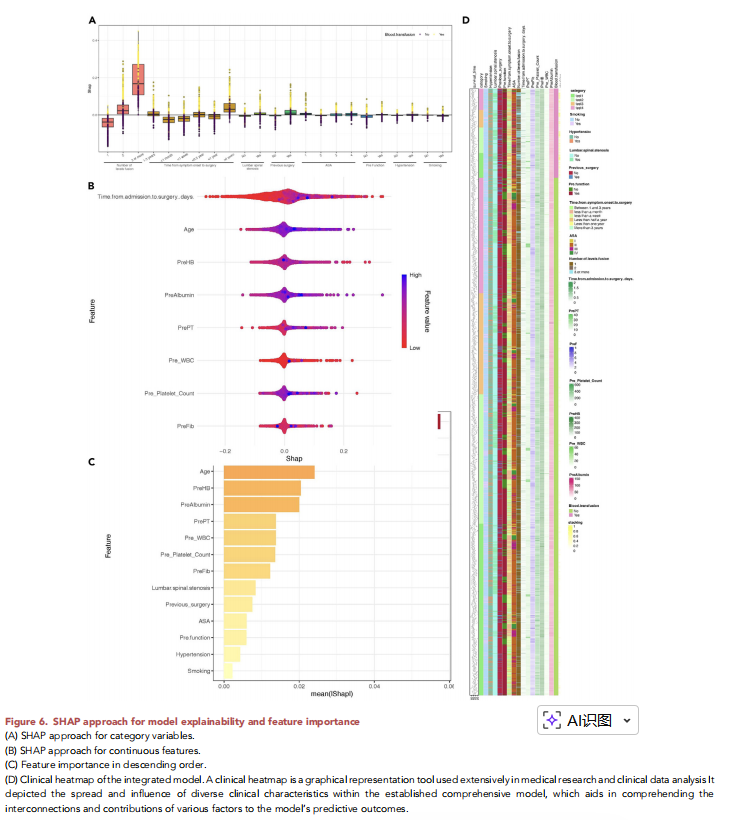
图5 基于SHAP方法的模型可解释性与特征重要性分析
7.研究开发的公开在线预测计算器,实现了从科研到临床的快速转化,可便捷辅助脊柱外科医生术前风险评估、用血资源规划与围术期管理,最终改善患者手术预后。
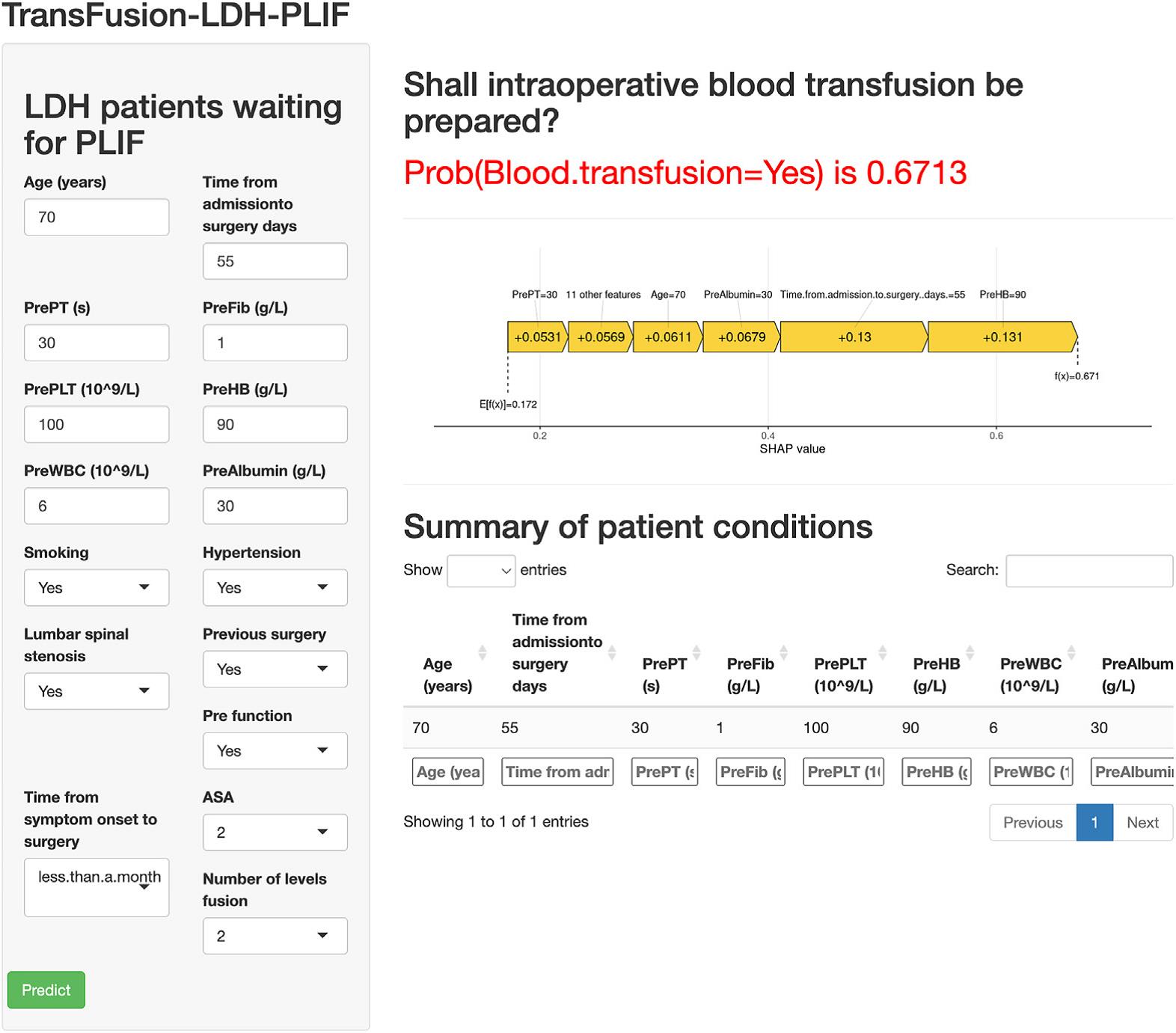
图6 在线网页计算器界面与预测示例图:网页计算器操作界面与预测结果示例,输入患者临床变量后,可直接输出输血预测概率与临床建议。
结论:
本研究基于中国多中心大样本LDH患者数据,系统构建并验证了用于预测PLIF术中输血风险的机器学习模型。结果表明,SA-SVM联合Stacking模型在不同数据集中的表现稳定,具有良好的区分能力与校准性能,展现出较强的泛化能力与临床应用潜力。此外,通过SHAP分析实现了模型的可解释性,增强了其在临床中的可接受性。本研究为基于机器学习的脊柱外科输血风险评估提供了重要依据,有望提升围术期决策的精准性与实用价值。
文献来源:
Liu Q, Chen AT, Li R, et al. Development and validation of machine learning models for intraoperative blood transfusion prediction in severe lumbar disc herniation. iScience. 2024;27(11):111106.
